大家好,我是腾意。
在任何将资源或服务提供给有限使用者的系统上,认证和授权都是两个必不可少的功能,认证用于身份鉴别,而授权则实现权限分派。Kubernetes以插件化的方式实现了这两种功能,且分别存在多种可用的插件。另外,它还支持准入控制机制,用于补充授权机制以实现更精细的访问控制功能。本篇主要讲解Kubernetes系统常用的认证、授权及准入控制机制。
1.1 访问控制概述
API Server作为Kubernetes集群系统的网关,是访问及管理资源对象的唯一入口,余下所有需要访问集群资源的组件,包括kube-controller-manager、kube-scheduler、kubelet和kube-proxy等集群基础组件、CoreDNS等集群的附加组件以及此前使用的kubectl命令等都要经由此网关进行集群访问和管理。这些客户端均要经由API Server访问或改变集群状态并完成数据存储,并由它对每一次的访问请求进行合法性检验,包括用户身份鉴别、操作权限验证以及操作是否符合全局规范的约束等。所有检查均正常完成且对象配置信息合法性检验无误之后才能访问或存入数据于后端存储系统etcd中,如图10-1所示。
客户端认证操作由API Server配置的一到多个认证插件完成。收到请求后,API Server依次调用为其配置的认证插件来认证客户端身份,直到其中一个插件可以识别出请求者的身份为止。授权操作由一到多个授权插件进行,它负责确定那些通过认证的用户是否有权限执行其发出的资源操作请求,如创建、读取、删除或修改指定的对象等。随后,通过授权检测的用户所请求的修改相关的操作还要经由一到多个准入控制插件的遍历检测,例如使用默认值补足要创建的目标资源对象中未定义的各字段、检查目标Namespace资源对象是否存在、检查是否违反系统资源限制,等等,而其中任何的检查失败都可能会导致写入操作失败。
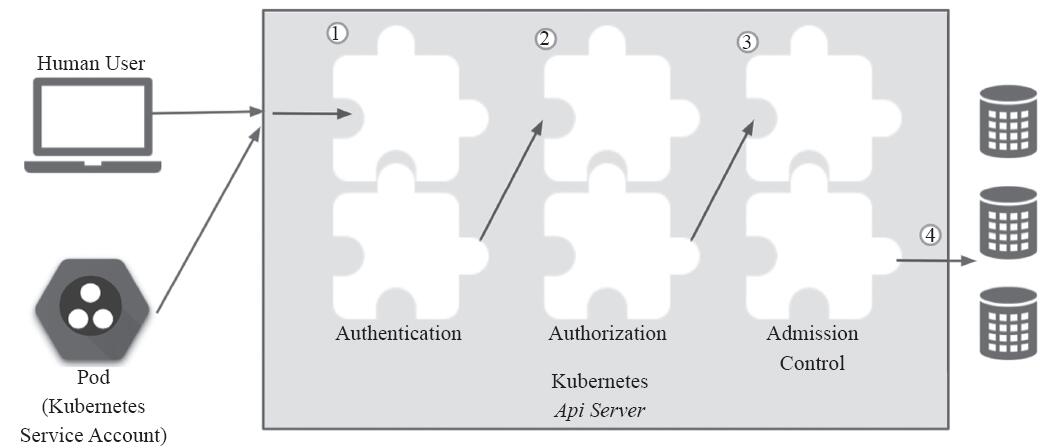
图10-1 用户账号、服务账号、认证、授权和准入控制
1.1.1 用户账户与用户组
Kubernetes并不会存储由认证插件从客户端请求中提取出的用户及所属组的信息,它们仅仅用于检验用户是否有权限执行其所请求的操作。客户端访问API服务的途径通常有三种:kubectl、客户端库或者直接使用REST接口进行请求,而可以执行此类请求的主体也被Kubernetes分为两类:现实中的“人”和Pod对象,它们的用户身份分别对应于常规用户(User Account)和服务账号(Service Account)。
·User Account(用户账号):一般是指由独立于Kubernetes之外的其他服务管理的用户账号,例如由管理员分发的密钥、Keystone一类的用户存储(账号库)、甚至是包含有用户名和密码列表的文件等。Kubernetes中不存在表示此类用户账号的对象,因此不能被直接添加进Kubernetes系统中。
·Service Account(服务账号):是指由Kubernetes API管理的账号,用于为Pod之中的服务进程在访问Kubernetes API时提供身份标识(identity)。Service Account通常要绑定于特定的名称空间,它们由API Server创建,或者通过API调用手动创建,附带着一组存储为Secret的用于访问API Server的凭据。
User Account通常用于复杂的业务逻辑管控,它作用于系统全局,故其名称必须全局唯一。相比较来说,Service Account隶属于名称空间,仅用于实现某些特定的操作任务,因此要轻量得多。这两类账号都可以隶属于一个或多个用户组。用户组只是用户账号的逻辑集合,它本身并没有操作权限,但附加于组上的权限可由其内部的所有用户继承,以实现高效的授权管理机制。Kubernetes有着以下几个内建的用于特殊目的的组。
·system:unauthenticated:未能通过任何一个授权插件检验的账号,即未通过认证测试的用户所属的组。
·system:authenticated:认证成功后的用户自动加入的一个组,用于快捷引用所有正常通过认证的用户账号。
·system:serviceaccounts:当前系统上的所有Service Account对象。
·system:serviceaccounts:
API请求要么与普通用户或服务账户进行绑定,要么被视为匿名请求。这意味着群集内部或外部的每个进程,包括由人类用户使用的kubectl,到节点上的kubelet,再到控制平面的成员组件,必须在向API服务器发出请求时进行身份验证,否则即被视为匿名用户。
1.1.2 认证、授权与准入控制基础
API Server处理请求的过程中,认证插件负责鉴定用户身份,授权插件用于操作权限许可鉴别,而准入控制则用于在资源对象的创建、删除、更新或连接(proxy)操作时实现更精细的许可检查,其相互间的作用关系如图10-1所示。
Kubernetes使用身份验证插件对API请求进行身份验证,支持的认证方式包括客户端证书、承载令牌(bearer tokens)、身份验证代理(authenticating proxy)或HTTP basic认证等。API Server接收到访问请求时,它将调用认证插件尝试将以下属性与访问请求相关联。
·Username:用户名,如kubernetes-admin等。
·UID:用户的数字标签符,用于确保用户身份的唯一性。
·Groups:用户所属的组,用于权限指派和继承。
·Extra:键值数据类型的字符串,用于提供认证时需要用到的额外信息。
API Server支持同时启用多种认证机制,但至少应该分别为Service Account和User Account各自启用一个认证插件。同时启用多种认证机制时,认证过程会以串行的方式进行,直到一种认证机制成功完成即结束。若认证失败,则服务器会响应401状态码,反之,请求者就会被识别为某个具体的用户(以其用户名进行标识),并且随后的操作都将以此用户身份来进行。
具体来说,API Server支持以下几种具体的认证方式,其中所有的令牌认证机制通常被统称为承载令牌认证。
1)X509客户端证书认证:客户端在请求报文中携带X509格式的数字证书用于认证,认证通过后,证书中的主体标识(Subject)将被识别为用户标识,其中的CN(Common Name)字段是用户名,O(Organization)是用户所属的组,如“/CN=ilinux/O=opmasters/O=admin”中,用户名为ilinux,其属于opmasters和admin两个组。
2)静态令牌文件(Static Token File):即保存着令牌信息的文件,由kube-apiserver的命令行选项--token-auth-file加载,且服务器启动后不可更改;HTTP客户端也能使用承载令牌进行身份验证,将令牌进行编码后,通过请求报文中的Authorization首部承载传递给API Server即可。
3)引导令牌(Bootstrap Tokens):一种动态管理承载令牌进行身份认证的方式,常用于简化新建Kubernetes集群的节点认证过程,需要通过--experimental-bootstrap-token-auth选项启用;有新的工作节点首次加入时,Master使用引导令牌确认节点身份的合法性之后自动为其签署数字证书以用于后续的安全通信,使用kubeadm join命令将节点加入kubeadm初始化的集群时使用的即是这种认证方式;这些令牌作为Secrets存储在kube-system命名空间中时,可以动态管理和创建它们,而Controller Manager包含一个TokenCleaner控制器,用于删除过期的引导令牌。
4)静态密码文件:用户名和密码等令牌以明文格式存储的CSV格式文件,由kube-apiserver使用--basic-auth-file选项进行加载;客户端在HTTP basic认证中将认证用户的用户名和密码编码后以承载令牌的格式进行认证。
5)服务账户令牌:由kube-apiserver自动启用,并可使用可选选项加载--service-account-key-file验证承载令牌的密钥,省略时将使用kube-apiserver自己的证书匹配的私钥文件;Service Account通常由API Server自动创建,并通过ServiceAccount准入控制器将其注入Pod对象,包括Service Account上的承载令牌,容器中的应用程序请求API Server的服务时将以此完成身份认证。
6)OpenID连接令牌:OAuth2的一种认证风格,由Azure AD、Salesforce和Google等OAuth2服务商所支持,协议的主要扩展是返回的附加字段,其中的访问令牌也称为ID令牌;它属于JSON Web令牌(JWT)类型,有着服务器签名过的常用字段,如email等;kube-apiserver启用这种认证功能的相关选项较多。
7)Webhook令牌:HTTP身份验证允许将服务器的URL注册为Webhook,并接收带有承载令牌的POST请求进行身份认证;客户端使用kubeconfig格式的配置文件,在文件中,“users”指的是API服务器Webhook,“clusters”指的是API Server。
8)认证代理:API Server支持从请求首部的值中识别用户,如X-Remote-User首部,它旨在与身份验证代理服务相结合,并由该代理设置相应的请求首部。
9)Keystone密码:借助于外部的Keystone服务器进行身份认证。
10)匿名请求:未被任何验证机制明确拒绝的用户即为匿名用户,其会被自动标识为用户名system:anonymous,并隶属于system:unauthenticated用户组;在API Server启用了除AlwaysAllow以外的认证机制时,匿名用户处于启用状态,不过,管理员可通过--anonymous-auth=false选项将其禁用。
另外,API Server还允许用户通过模拟(impersonation)首部来冒充另一个用户,这些请求可以以手动的方式覆盖请求中用于身份验证的用户信息。例如,管理员可以使用此功能临时模拟其他用户来查看请求是否被拒绝进行授权策略调试。
API Server是一种REST API,除了身份认证信息之外,一个请求报文还需要提供操作方法及其目标对象,如针对某Pod资源对象进行的创建、查看、修改或删除操作等,具体来说,请求报文包含如下信息。
·API:用于定义请求的目标是否为一个API资源。
·Request path:请求的非资源型路径,如/api或/healthz。
·API group:要访问的API组,仅对资源型请求有效;默认为“core API group”。
·Namespace:目标资源所属的名称空间,仅对隶属于名称空间类型的资源有效。
·API request verb:API请求类的操作,即资源型请求(对资源执行的操作),包括get、list、create、update、patch、watch、proxy、redirect、delete和deletecollection等。
·HTTP request verb:HTTP请求类的操作,即非资源型请求要执行的操作,如get、post、put和delete。
·Resource:请求的目标资源的ID或名称。
·Subresource:请求的子资源。
为了核验用户的操作许可,成功通过身份认证后的操作请求还需要转交给授权插件进行许可权限检查,以确保其拥有执行相应的操作的许可。API Server主要支持使用四类内建的授权插件来定义用户的操作权限。
·Node:基于Pod资源的目标调度节点来实现的对kubelet的访问控制。
·ABAC:attribute-based access control,基于属性的访问控制。
·RBAC:role-based access control,基于角色的访问控制。
·Webhook:基于HTTP回调机制通过外部REST服务检查确认用户授权的访问控制。
另外,还有AlwaysDeny和AlwaysAllow两个特殊的授权插件,其中AlwaysDeny(总是拒绝)仅用于测试,而AlwaysAllow(总是允许)则用于不期望进行授权检查时直接于授权检查阶段放行的所有操作请求。启动API Server时,“--authorization-mode”选项用于定义要启用的授权机制,多个选项彼此之间以逗号分隔。
而准入控制器(Admission Controller)则用于在客户端请求经过身份验证和授权检查之后,但在对象持久化存储etcd之前拦截请求,用于实现在资源的创建、更新和删除操作期间强制执行对象的语义验证等功能,读取资源信息的操作请求不会经由准入控制器的检查。API Server内置了许多准入控制器,常用的包含如下几种。不过,其中的个别控制器仅在较新版本的Kubernetes中才受支持。
1)AlwaysAdmit:允许所有请求。
2)AlwaysDeny:拒绝所有请求,仅应该用于测试。
3)AlwaysPullImages:总是下载镜像,即每次创建Pod对象之前都要去下载镜像,常用于多租户环境中以确保私有镜像仅能够被拥有权限的用户使用。
4)NamespaceLifecycle:拒绝于不存在的名称空间中创建资源,而删除名称空间将会级联删除其下的所有其他资源。
5)LimitRanger:可用资源范围界定,用于监控对设置了LimitRange的对象所发出的所有请求,以确保其资源请求不会超限。
6)ServiceAccount:用于实现Service Account管控机制的自动化,实现创建Pod对象时自动为其附加相关的Service Account对象。
7)PersistentVolumeLabel:为那些由云计算服务商提供的PV自动附加region或zone标签,以确保这些存储卷能够正确关联且仅能关联到所属的region或zone。
8)DefaultStorageClass:监控所有创建PVC对象的请求,以保证那些没有附加任何专用StorageClass的请求会自动设定一个默认值。
9)ResourceQuota:用于对名称空间设置可用资源的上限,并确保在其中创建的任何设置了资源限额的对象都不会超出名称空间的资源配额。
10)DefaultTolerationSeconds:如果Pod对象上不存在污点宽容期限,则为它们设置默认的宽容期,以宽容“notready:NoExecute”和“unreachable:NoExctute”类的污点5分钟时间。
11)ValidatingAdmissionWebhook:并行调用匹配当前请求的所有验证类的Webhook,任何一个校验失败,请求即失败。
12)MutatingAdmissionWebhook:串行调用匹配当前请求的所有变异类的Webhook,每个调用都可能会更改对象。
早期的准入控制器代码需要由管理员编译进kube-apiserver中才能使用,其实现方式缺乏灵活性。于是,Kubernetes自1.7版本引入了Initializers和External Admission Webhooks来尝试突破此限制,而且自1.9版本起,External Admission Webhooks被分为MutatingAdmission- Webhook和ValidatingAdmissionWebhook两种类型,分别用于在API中执行对象配置的变异和验证操作。检查期间,只有那些顺利通过所有准入控制器检查的资源操作请求的结果才能保存到etcd中,实现持久存储,换句话讲,任何一个准入控制器的拒绝都将导致请求 失败。
1.2 服务账户管理与应用
运行过程中,Pod资源里的容器进程在某些场景中需要调用Kubernetes API或者其他类型的服务,而这些服务通常需要认证客户端身份,如调度器、Pod控制器或节点控制器,甚至是获取启动容器的镜像访问的私有Registry服务等。服务账户就是用于让Pod对象内的容器进程访问其他服务时提供身份认证信息的账户。一个Service Account资源一般由用户名及相关的Secret对象组成。
1.2.1 Service Account自动化
细心的读者或许已经注意到,此前创建的每个Pod资源都自动关联了一个存储卷,并由其容器挂载至/var/run/secrets/kubernetes.io/serviceaccount目录,例如,下面由“kubectl describe pod”命令显示的某Pod对象描述信息的片断:
Containers: …… Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-bq6zc (ro) …… Volumes: default-token-bq6zc: Type: Secret (a volume populated by a Secret) SecretName: default-token-bq6zc Optional: false
挂载点目录中通常存在三个文件:ca.crt、namespace和token,其中,token文件保存了Service Account的认证token,容器中的进程使用它向API Server发起连接请求,进而由认证插件完成用户认证并将其用户名传递给授权插件。
每个Pod对象都只有一个服务账户,若创建Pod资源时未予以明确指定,则名为ServiceAccount的准入控制器会为其自动附加当前名称空间中默认的服务账户,其名称通常为default。下面的命令显示了default这个服务账户的详细信息:
~]$ kubectl describe serviceaccount default Name: default …… Mountable secrets: default-token-bq6zc Tokens: default-token-bq6zc Events: <none>
Kubernetes系统通过三个独立的组件间的相互协作来实现服务账户的自动化,三个组件具体为:Service Account准入控制器、令牌控制器(token controller)和Service Account账户控制器。Service Account控制器负责为名称空间管理相应的资源,并确保每个名称空间中都存在一个名为“default”的Service Account对象。Service Account准入控制器是API Server的一部分,负责在创建或更新Pod时对其按需进行Service Account对象相关信息的修改,这包括如下操作。
·若Pod没有明确定义使用的ServiceAccount对象,则将其设置为“default”。
·确保Pod明确引用的ServiceAccount已存在,否则请求将被拒绝。
·若Pod对象中不包含ImagePullSecerts,则把Service Account的ImagePullSecrets添加于其上。
·为带有访问API的令牌的Pod添加一个存储卷。
·为Pod对象中的每个容器添加一个volumeMounts,挂载至/var/run/secrets/kubernetes.io/serviceaccount。
令牌控制器是controller-manager的子组件,工作于异步模式。其负责完成的任务具体如下。
·监控Service Account的创建操作,并为其添加用于访问API的Secret对象。
·监控Service Account的删除操作,并删除其相关的所有Service Account令牌密钥。
·监控Secret对象的添加操作,确保其引用的Service Account已存在,并在必要时为Secret对象添加认证令牌。
·监控Secret对象的删除操作,以确保删除每个Service Account中对此Secret的引用。
需要注意的是,为确保完整性等,必须为kube-controller-manager使用“--service-account-private-key-file”选项指定一个私钥文件,以用于对生成的服务账户令牌进行签名,此私钥文件必须是pem格式。类似地,还要为kube-apiserver使用“--service-account-key-file”指定与前面的私钥配对儿的公钥文件,以用于在认证期间对认证令牌进行校验。
1.2.2 创建服务账户
Service Account是Kubernetes API上的一种资源类型,它隶属于名称空间,用于让Pod对象内部的应用程序在与API Server通信时完成身份认证。事实上,每个名称空间都有一个名为default的默认资源对象,如下面的命令及其结果所示,其可用于让Pod对象有权限读取同一名称空间中的其他资源对象的元数据信息。需要赋予Pod对象更多操作权限时,则应该由用户按需创建自定义的Service Account资源:
~]$ kubectl get serviceaccounts --all-namespaces NAMESPACE NAME SECRETS AGE default default 1 2h kube-public default 1 2h kube-system default 1 2h
每个Pod对象均可附加其所属名称空间中的一个Service Account资源,且只能附加一个。不过,一个Service Account资源可由其所属名称空间中的多个Pod对象共享使用。创建Pod资源时,用户可使用“spec.serviceAccountName”属性直接指定要使用的Service Account对象,或者省略此字段而由其自动附加当前名称空间中默认的Service Account(default)。
可使用资源配置文件创建Service Account资源,也可直接使用“kubectl create servic-eaccount”命令进行创建,提供认证令牌的Secret对象会由命令自动创建完成。下面的配置清单是一个ServiceAccount资源示例,它仅指定了创建名为sa-demo的服务账户,其余的信息则交由系统自动生成:
apiVersion: v1 kind: ServiceAccount metadata: name: sa-demo namespace: default
创建Pod对象时,可为Pod对象指定使用自定义的服务账户,从而实现自主控制Pod对象资源的访问权限。Pod向API Server发出请求时,其携带的认证令牌在通过认证后将由授权插件来判定相关的Service Account是否有权限访问其所请求的资源。Kubernetes支持多种授权插件,由管理员负责选定及配置,RBAC是目前较为主流的选择。
1.2.3 调用imagePullSecret资源对象
ServiceAccount资源还可以基于spec.imagePullSecret字段附带一个由下载镜像专用的Secret资源组成的列表,用于在进行容器创建时,从某私有镜像仓库下载镜像文件之前进行服务认证。下面的示例定义了一个有着从本地私有镜像仓库harbor中下载镜像文件时用于认证的Secret对象信息的ServiceAccount:
apiVersion: v1 kind: ServiceAccount metadata: name: image-download-sa imagePullSecrets: - name: local-harbor-secret
其中,local-harbor-secret是docker-registry类型的Secret对象,由用户提前手动创建,它可以通过键值数据提供docker仓库服务器的地址、接入服务器的用户名、密码及用户的电子邮件等信息。认证通过后,引用了此ServiceAccount的Pod资源即可从指定的镜像仓库中下载由image字段指定的镜像文件。
1.3 X.509数字证书认证
Kubernetes支持的HTTPS客户端证书认证、token认证及HTTP basic认证几种认证方式中,基于SSL/TLS协议的客户端证书认证以其安全性高且易于实现等特性,而成为主要使用的认证方式之一。
SSL/TLS最常见的使用场景是将X.509证书与服务器端相关联,但不为客户端使用证书。这意味着客户端可以验证服务端的身份,但服务端无法验证客户端的身份(至少不能通过SSL/TLS协议进行)。这很容易理解,毕竟SSL/TLS安全性最初是为互联网应用开发,保护客户端反而是高优先级的需求,例如,在需要连接到银行的网站时需要确保该网站是真实的等,如图10-2所示。
此外,验证客户端时,使用其他机制(如HTTP基本认证)通常会更容易些,而且这些机制不会产生生成和分发X.509证书的高昂维护开销。不过,安全性要求较高的场景中,使用组织私有的证书分发系统也一样能够使用数字证书进行客户端认证。图10-3展示了服务端与客户端的双向认证机制。
服务端与客户端互相认证的场景中,双方各自需要配备一套证书,并拥有信任的签证机构的证书列表。使用私有签证机构颁发的数字证书时,用户通常需要手动将此私有签证机构的证书添加到信任的签证机构列表中。
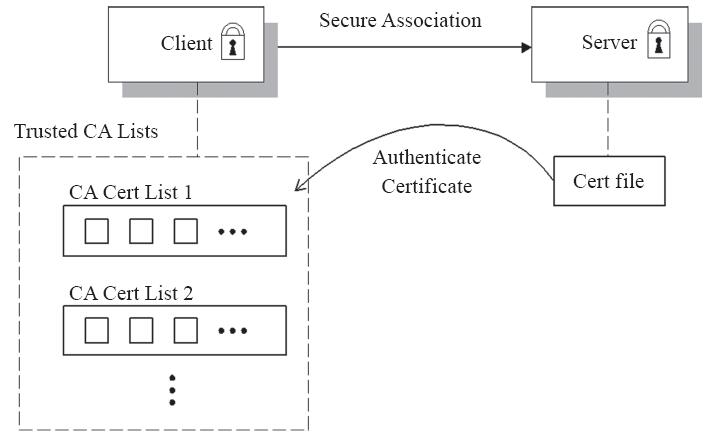
图10-2 SSL/TLS服务端认证(图片来源:Red Hat Inc.)
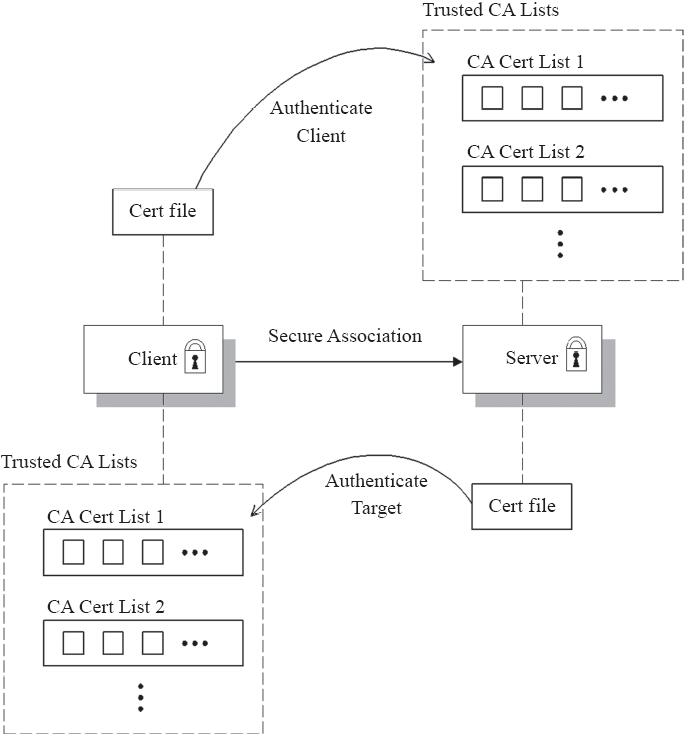
图10-3 SSL/TLS双向认证(图片来源:Red Hat Inc.)
1.3.1 Kubernetes中的SSL/TLS认证
构建安全基础通信环境的Kubernetes集群时,需要用到TLS及数字证书的通信场景有很多种,如图10-4所示。API Server是整个Kubernetes集群的通信网关,controller-manager、scheduler、kubelet及kube-proxy等均需要经由API Server与etcd通信完成资源状态信息的获取及更新等。同样出于安全通信的目的,master的各组件(API Server、controller-manager和scheduler)需要基于SSL/TLS向外提供服务,而且与集群内部组件间进行通信时(主要是各节点上的kubelet和kube-proxy)还需要进行双向身份验证。
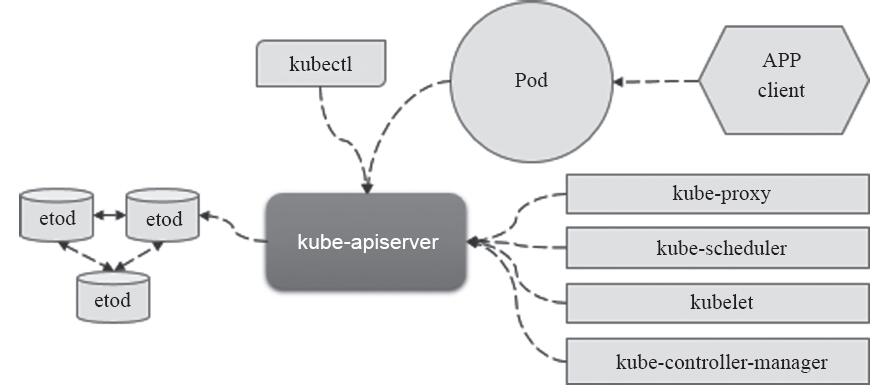
图10-4 Kubernetes的SSL/TLS通信
Kubernetes集群中各资源的状态信息,包括Secret对象中的敏感信息等均以明文方式存储于etcd中,因此,etcd集群内各节点间的通信,以及各节点与其客户端(主要是API sevrver)之间的通信都应该以加密的方式进行,并需进行身份验证。
1)etcd集群内对等节点通信: etcd集群内各节点间的集群事务通信,默认监听于TCP的2380端口,基于SSL/TLS通信时需要peer类型的数字证书,可实现节点间的身份认证及通信安全,这些证书需要由一个专用CA进行管理。
2)etcd服务器与客户端通信: etcd的REST API服务,默认监听于TCP的2379端口,用于接收并响应客户端请求,基于SSL/TLS通信,支持服务端认证和双向认证,而且要使用一个专用CA来管理此类证书;kube-apiserver就是etcd服务的主要客户端。
API Server与其客户端之间采用HTTPS通信可兼顾实现通信与认证的功能,它们之间通信的证书可由同一个CA进行管理,其客户端大体可以分为如下三类。
·控制平面的kube-scheduler和kube-controller-manager。
·工作节点组件kubelet和kube-proxy:初次接入集群时,kubelet可自动生成私钥和证书签署请求,并由Master为其自动进行证书签名和颁发,这就是所谓的tls bootstraping。
·kubelet及其他形式的客户端,如Pod对象等。
集群上运行的应用(Pod)同其客户端的通信经由不可信的网络传输时也可能需要用到TLS/SSL协议,如Nginx Pod与其客户端间的通信,客户端来自于互联网时,此处通常需要配置一个公信的服务端证书。
1.3.2 客户端配置文件kubeconfig
包括kubectl、kubelet和kube-controller-manager等在内的API Server的各类客户端都可以使用kubeconfig配置文件提供接入多个集群的相关配置信息,包括各API Server的URL及认证信息等,而且能够设置成不同的上下文环境,并在各环境之间快速切换,如图10-5所示。

图10-5 kubectl和kubeconf ig
使用kubeadm初始集群后生成的/etc/kubernetes/admin.conf文件即为kubeconfig格式的配置文件,其由kubeadm init命令自动生成,可由kubectl加载(默认路径为$HOME/.kube/config)后用于接入服务器。“kubectl config view”命令能够显示当前正在使用的配置文件,下面的命令结果打印了文件中配置的集群列表、用户列表、上下文列表以及当前使用的上下文(current-context)等:
[root@master ~]# kubectl config view apiVersion: v1 clusters: - cluster: certificate-authority-data: REDACTED server: https://172.16.0.70:6443 name: kubernetes contexts: - context: cluster: kubernetes user: kubernetes-admin name: kubernetes-admin@kubernetes current-context: kubernetes-admin@kubernetes kind: Config preferences: {} users: - name: kubernetes-admin user: client-certificate-data: REDACTED client-key-data: REDACTED
事实上,任何类型的API Server客户端都可以使用kubeconfig进行配置,例如KubernetesNode之上的kubelet和kube-proxy也需要将其用到的认证信息保存于专用的kubeconfig文件中,并通过--kubeconfig选项进行加载。kubeconfig文件的定义中包含以下几项主要的配置,它们彼此之间的关系表示也由图10-6给出了。
·clusters:集群列表,包含访问API Server的URL和所属集群的名称等。
·users:用户列表,包含访问API Server时的用户名和认证信息。
·contexts:kubelet的可用上下文列表,由用户列表中的某特定用户名称和集群列表中的某特定集群名称组合而成。
·current-context:kubelet当前使用的上下文名称,即上下文列表中的某个特定项。
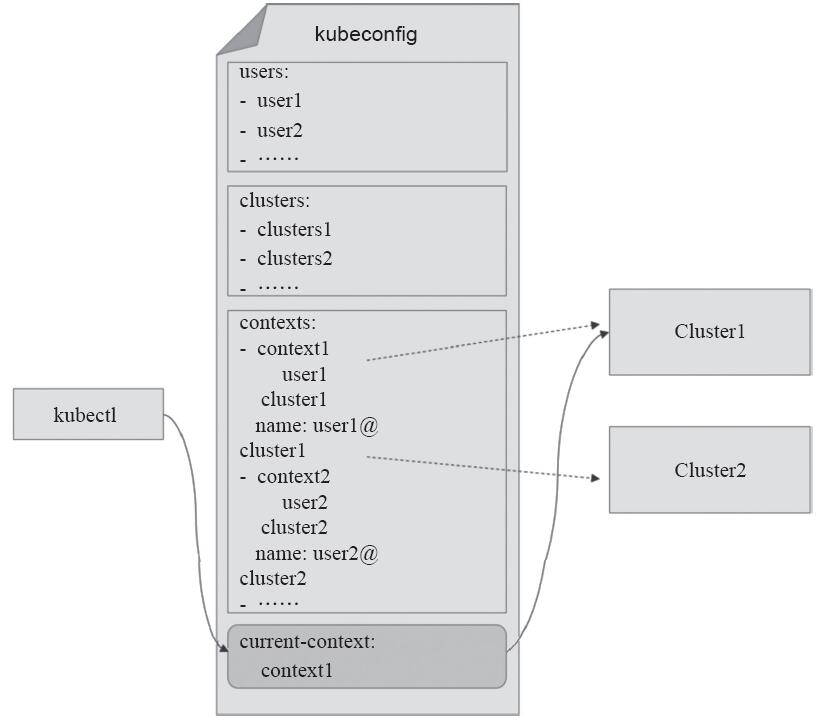
图10-6 kubeconfig文件格式示意图
用户也可以按需自定义相关的配置信息于kubeconfig配置文件中,以实现使用不同的用户账户接入集群等功能。kubeconfig是一个文本文件,虽然支持使用文本处理工具直接进行编辑,但这里建议用户使用“kubectl config”命令进行设定,它能够自动进行语法检测等额外功能。kubectl config命令的常用操作包含如下几项。
·kubectl config view:打印kubeconfig文件内容。
·kubectl config set-cluster:设置kubeconfig的clusters配置段。
·kubectl config set-credentials:设置kubeconfig的users配置段。
·kubectl config set-context:设置kubeconfig的contexts配置段。
·kubectl config use-context:设置kubeconfig的current-context配置段。
使用kubeadm部署的Kubernetes集群默认提供了拥有集群管理权限的kubeconfig配置文件/etc/kubernetes/admin.conf,它可被复制到任何有着kubectl的主机上以用于管理整个集群。除此之外,管理员还可以创建其他基于SSL/TLS认证的自定义用户账号,以授予非管理员级的集群资源使用权限,其配置过程由两部分组成:一是为用户创建专用私钥及证书文件,二是将其配置于某kubeconfig文件中。下面给出其具体的实现过程,并借此创建将一个测试用户kube-user1用于后文中的授权测试。
第一步, 为目标用户账号kube-user1创建私钥及证书文件,保存于/etc/kubernetes/pki目录中。
提示 本步骤中的操作需要在Master节点上以root用户的身份执行。
1)生成私钥文件,注意其权限应该为600以阻止其他用户随意获取,这里在Master节点上以root用户进行操作,并将文件放置于/etc/kubernetes/pki专用目录中:
~]# cd /etc/kubernetes/pki ~]# (umask 077; openssl genrsa -out kube-user1.key 2048)
2)创建证书签署请求,-subj选项中CN的值将被kubeconfig作为用户名使用,O的值将被识别为用户组:
~]# openssl req -new -key kube-user1.key -out kube-user1.csr -subj "/CN=kube-user1/ O=kubeusers"
3)基于kubeadm安装Kubernetes集群时生成的CA签署证书,这里设置其有效时长为3650天:
~]# openssl x509 -req -in kube-user1.csr -CA ca.crt -CAkey ca.key \ -CAcreateserial -out kube-user1.crt -days 3650
4)验证证书信息(可选):
~]# openssl x509 -in kube-user1.crt -text -noout
第二步, 以默认的管理员kubernetes-admin@kubernetes为新建的kube-user1设定kube-config配置文件。配置结果将默认保存于当前系统用户的.kube/config文件中,当然也可以为kubectl使用--kubeconfig选项指定自定义的专用文件路径。
1)配置集群信息,包括集群名称、API Server URL和CA证书,若集群信息已然存在,则可省略此步,另外,提供的新配置不能与现有配置中的集群名称相同,否则将覆盖它们:
~]$ kubectl config set-cluster kubernetes --embed-certs=true \ --certificate-authority=/etc/kubernetes/pki/ca.crt --server="https://172.16. 0.70:6443"
2)配置客户端证书及密钥,用户名信息会通过命令从证书Subject的CN值中自动提取,例如前面创建csr时使用的“CN=kube-user1”,而组名则来自于“O=kubeusers”的定义:
~]$ kubectl config set-credentials kube-user1 --embed-certs=true \ --client-certificate=/etc/kubernetes/pki/kube-user1.crt \ --client-key=/etc/kubernetes/pki/kube-user1.key
3)配置context,用来组合cluster和credentials,即访问的集群的上下文。如果为管理多个集群而设置了多个环境,则可以使用use-context来进行切换:
~]$ kubectl config set-context kube-user1@kubernetes --cluster=kubernetes --user= kube-user1
4)最后指定要使用的上下文,切换为以kube-user1访问集群:
~]$ kubectl config use-context kube-user1@kubernetes
5)测试访问集群资源,不过在启用RBAC的集群上执行命令时,kube-user1并未获得集群资源的访问权限,因此会出现错误提示:
~]$ kubectl get pods Error from server (Forbidden): pods is forbidden: User "kube-user1" cannot list pods in the namespace "default"
此时,若需切换至管理员账号,则可使用“kubectl config use-context kubernetes-admin@kubernetes”命令来完成。另外,临时使用某context时,不必设置current-context,只需要为kubectl命令使用--context选项指定目标context的名称即可,如“kubectl--context= kube-user1@kubernetes get pods”。
1.3.3 TLS bootstrapping机制
新的工作节点接入集群时需要事先配置好相关的证书和私钥等以进行安全通信,管理员既可以手动提供相关的配置,也可以选择由kubelet自行生成私钥和自签证书。集群略具规模后,第一种方式无疑会为管理员带来不小的负担,但其对于保障集群安全运行却又必不可少。第二种方式降低了管理员的工作量,却也损失了PKI本身所具有的诸多优势。综合上述两种方案,取长补短之后,Kubernetes采用了一种新的方案:由kubelet自行生成私钥和证书签署请求,而后发送给集群上的证书签署进程(CA),由管理员验证请求后予以签署或直接控制器进程自动统一签署。这种方式即为Kubelet TLS Bootstrapping机制,它实现了前述第一种方式的功能,却基本上不会增加管理员工作量。
然而,启用了kubelet bootstrap功能之后,任何kubelet进程都可以向API Server发起签证请求并加入到集群中,包括那些来自于非计划或非授权主机的kubelet,这必将增大管理签证操作时的识别工作量。此时,就需要配合使用某种认证机制对发出请求的kubelet加以认证,而后仅放行那些通过认证的签证请求。API Server使用了一个基于认证令牌对“system:bootstrappers”组内的用户完成认证的认证器。controller-manager会用到这个用户组配置默认的审批控制器(approval controller)适用的审批范围,它依赖于由管理员将此token正确绑定于RBAC策略,以限制其仅能用于签证操作相关的流程之中。
提示 kubeadm启用了节点加入集群时的证书自动签署功能,因此加入过程在kubeadm join命令成功后即完成。
请求证书时,kubelet要使用含有bootstrap token的kubeconfig文件向kube-apiserver发送请求,此kubeconfig在credentials中指定要调用的token文件名称必须是kubelet-bootstrap。若指定的kubeocnfig配置文件不存在,则kubelet会转而使用bootstrap token从API Server中自动请求证书。证书请求审批通过后,kubelet把接收到的证书和私钥的相关信息存储于--kubeconfig选项指定的文件中,而证书和私钥文件则存储于--cert-dir选项指定的目录下。
kube-controller-manager内部有一个用于证书颁发的控制循环,它是采用了类似于cfssl签证器格式的自动签证器,颁发的所有证书都仅有一年有效期限。签证依赖于CA提供加密组件支撑,此CA还必须被kube-apiserver的“--client-ca-file”选项指定的CA信任以用于认证。
Kubernetes 1.8之后的版本中使用的csrapproving审批控制器内置于kube-controller-manager中,并且默认为启用状态。此审批控制器使用SubjectAccessview API确认给定的用户是否有权限请求CSR(证书签署请求),而后再根据授权结果判定是否予以签署。不过,为了避免同其他审批器发生冲突,内建的审批器并不显式拒绝CSR,而只是忽略它们。
1.4 基于角色的访问控制:RBAC
RBAC(Role-Based Access Control,基于角色的访问控制)是一种新型、灵活且使用广泛的访问控制机制,它将权限授予“角色”(role)之上,这一点有别于传统访问控制机制中将权限直接赋予使用者的方式。
在RBAC中,用户(User)就是一个可以独立访问计算机系统中的数据或者用数据表示的其他资源的主体(Subject)。角色是指一个组织或任务中的工作或者位置,它代表了一种权利、资格和责任。许可(Permission)就是允许对一个或多个客体(Object)执行的操作。一个用户可经授权而拥有多个角色,一个角色可由多个用户构成;每个角色可拥有多种许可,每个许可也可授权给多个不同的角色。每个操作可施加于多个客体(受控对象),每个客体也可以接受多个操作。RBAC中的动作、主体及客体如图10-7所示。
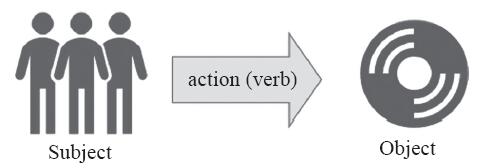
图10-7 RBAC中的主体、动作及客体
如其名字所示,RBAC的基于“角色”(role)这一核心组件实现了权限指派,具体实现中,它为账号赋予一到多个角色从而让其具有角色之上的权限,其中的账号可以是用户账号、用户组、服务账号及其相关的组等,而同时关联至多个角色的账号所拥有的权限是多个角色之上的权限集合。RBAC中的用户、角色及权限的关系如图10-8所示。
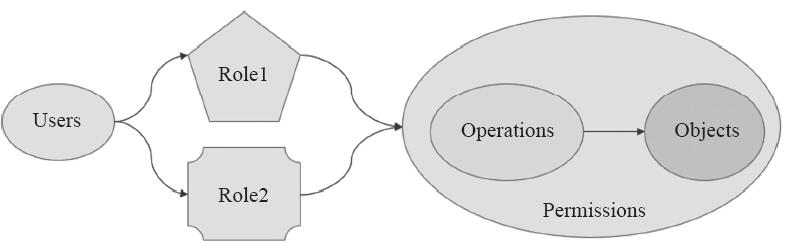
图10-8 RBAC中的用户、角色及权限
1.4.1 RBAC授权插件
RBAC是一种操作授权机制,用于界定“谁”(subject)能够或不能够“操作”(verb)哪个或哪类“对象”(object)。动作的发出者即“主体”,通常以“账号”为载体,它既可以是常规用户(User Account),也可以是服务账号(Service Account)。“操作”(verb)用于表明要执行的具体操作,包括创建、删除、修改和查看等,对应于kubectl来说,它通常由create、apply、delete、update、patch、edit和get等子命令来给出。而“客体”则是指操作施加于的目标实体,对Kubernetes API来说主要是指各类的资源对象以及非资源型URL。
提示 Kubernetes自1.5版起引入RBAC,1.6版本中将其升级为Beta级别,并成为kubeadm安装方式下的默认选项。而后,直到1.8版本,它才正式升级为stable级别。
相对于ABAC和Webhook等授权机制来说,RBAC具有如下优势。
1)对集群中的资源和非资源型URL的权限实现了完整覆盖。
2)整个RBAC完全由少数几个API对象实现,而且同其他API对象一样可以用kubectl或API调用进行操作。
3)支持权限的运行时调整,无须重新启动API Server。
API Server是RESTful风格的API,各类客户端基于HTTP的请求报文(首部)发送身份认证信息并由认证插件完成身份验证,而后通过HTTP的请求方法指定对目标对象的操作请求并由授权插件进行授权检查,而操作的对象则是借助URL路径指定的REST资源。
图10-9对比给出了HTTP Verb和Kubernetes APIServer Verb的对应关系。

图10-9 HTTP Verb与API Server Verb
图10-10所描述的过程中,运行于API Server之上的授权插件RBAC负责确定某账号是否有权限对目标资源发出指定的操作,它们都属于“许可”(permission)类型的授权,不存在任何“拒绝”权限。
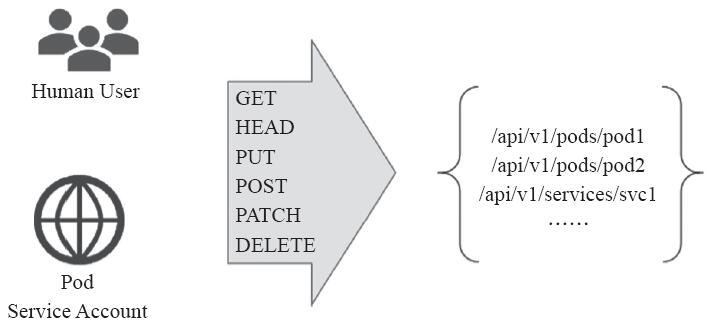
图10-10 Kubernetes RBAC简要模型
RBAC授权插件支持Role和ClusterRole两类角色,其中Role作用于名称空间级别,用于定义名称空间内的资源权限集合,而ClusterRole则用于组织集群级别的资源权限集合,它们都是标准的API资源类型。一般来说,ClusterRole的许可授权作用于整个集群,因此常用于控制Role无法生效的资源类型,这包括集群级别的资源(如Nodes)、非资源类型的端点(如/healthz)和作用于所有名称空间的资源(例如,跨名称空间获取任何资源的权限)。
对这两类角色进行赋权时,需要用到RoleBinding和ClusterRoleBinding这两种资源类型。RoleBinding用于将Role上的许可权限绑定到一个或一组用户之上,它隶属于且仅能作用于一个名称空间。绑定时,可以引用同一名称中的Role,也可以引用集群级别的ClusterRole。而ClusterRoleBinding则把ClusterRole中定义的许可权限绑定在一个或一组用户之上,它仅可以引用集群级别的ClusterRole。Role、RoleBinding、ClusterRole和ClusterRoleBinding的关系如图10-11所示。
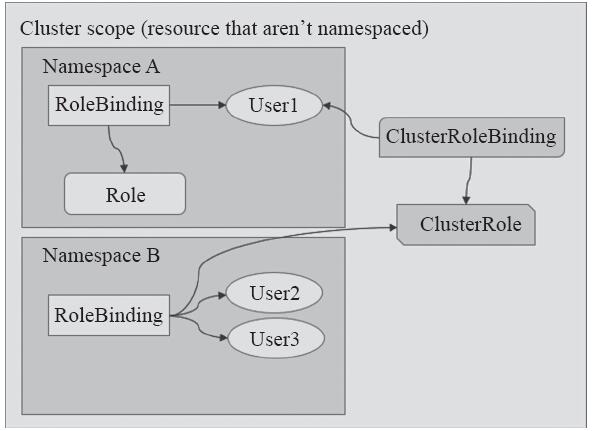
图10-11 Role、RoleBinding、ClusterRole和ClusterRoleBinding
一个名称空间中可以包含多个Role和RoleBinding对象,类似地,集群级别也可以同时存在多个ClusterRole和ClusterRoleBinding对象。而一个账户也可经由RoleBinding或ClusterRoleBinding关联至多个角色,从而具有多重许可授权。
1.4.2 Role和RoleBinding
Role仅是一组许可(permission)权限的集合,它描述了对哪些资源可执行何种操作,资源配置清单中使用rules字段嵌套授权规则。下面是一个定义在testing名称空间中的Role对象的配置清单示例,它设定了读取、列出及监视Pod和Service资源的许可权限:
kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: namespace: testing name: pods-reader rules: - apiGroups: [""] # "" 表示core API group resources: ["pods", "pods/log"] verbs: ["get", "list", "watch"]
类似上面的Role对象中的rules也称为PolicyRule,用于定义策略规则,不过它不包含规则应用的目标,其可以内嵌的字段包含如下几个。
1)apiGroups<[]string>:包含了资源的API组的名称,支持列表格式指定的多个组,空串("")表示核心组。
2)resourceNames<[]string>:规则应用的目标资源名称列表,可选,缺省时意味着指定资源类型下的所有资源。
3)resources<[]string>:规则应用的目标资源类型组成的列表,例如pods、deployments、daemonsets、roles等,ResourceAll表示所有资源。
4)verbs<[]string>:可应用至此规则匹配到的所有资源类型的操作列表,可用选项有get、list、create、update、patch、watch、proxy、redirect、delete和deletecollection;此为必选字段。
5)nonResourceURLs<[]string>:用于定义用户应该有权限访问的网址列表,它并非名称空间级别的资源,因此只能应用于ClusterRole和ClusterRoleBinding,在Role中提供此字段的目的仅为与ClusterRole在格式上兼容。
绝大多数资源均可通过其资源类型的名称引用,如“pods”或“services”等,这些名字与它们在API endpoint中的形式相同。不过,有些资源类型还支持子资源(subresource),例如Pod对象的/log,Node对象的/status等,它们的URL格式通常形如如下表示:
GET /api/v1/namespaces/{namespace}/pods/{name}/log
在RBAC角色定义中,如果要引用这种类型的子资源,则需要使用“resource/subre-source“的格式,如上面示例规则中的“pods/log”。另外,还可以通过直接给定资源名称(resourceName)来引用特定的资源,此时支持使用的操作通常仅为get、delete、update和patch,也可使用这四个操作的子集实现更小范围的可用操作限制。
除了编写配置清单创建Role资源之外,还可以直接使用“kubectl create role”命令进行快速创建,例如,下面的命令在testing名称空间中创建了一个名为services-admin的角色:
~]$ kubectl create role services-admin --verb="*" --resource="services,servic es/*" -n testing
将清单中的Role资源也创建于集群上之后,testing名称空间中就有了pods-reader和services-admin两个角色,但角色本身并不能作为动作的执行主体,它们需要“绑定”(Role-Binding)到主体(如user、group或service account)之上才能发生作用。
RoleBinding用于将Role中定义的权限赋予一个或一组用户,它由一组主体,以及一个要引用来赋予这组主体的Role或ClusterRole组成。需要注意的是,RoleBinding仅能够引用同一名称空间中的Role对象完成授权,例如,下面配置清单中的RoleBinding于testing名称空间中将pods-reader角色赋给了用户kube-user1,从而使得kube-user1拥了此角色之上的所有许可授权:
kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: resources-reader namespace: testing subjects: - kind: User name: kube-user1 apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: pods-reader apiGroup: rbac.authorization.k8s.io
将此RoleBinding资源应用到集群中,kube-user1用户便有了读取testing名称空间中pods资源的权限。将kubectl的配置上下文切换至kube-user1用户,分别对pods和services资源发起访问请求测试,由下面的命令结果可以看出,它能够请求读取pods资源,但对其他任何资源的任何操作请求都将被拒绝:
~]$ kubectl config use-context kube-user1@kubernetes Switched to context "kube-user1@kubernetes". ~]$ kubectl get pods -n testing No resources found. ~]$ kubectl get services -n testing Error from server (Forbidden): services is forbidden: User "kube-user1" cannot list services in the namespace "testing"
RoleBinding资源也能够直接在命令行中创建。例如,将kubectl的上下文切换为kubernetes-admin用户,将前面创建的services-admin角色绑定于kube-user1之上,可以使用如下命令进行:
~]$ kubectl config use-context kubernetes-admin@kubernetes ~]$ kubectl create rolebinding admin-services --role=services-admin --user=kube- user1 -n testing rolebinding.rbac.authorization.k8s.io "admin-services" created
再次切换到kube-user1用户,进行services资源的访问测试,由下面的命令结果可知,它能够访问services资源,而不再是拒绝权限:
~]$ kubectl config use-context kube-user1@kubernetes ~]$ kubectl get services -n testing No resources found.
事实上,通过admin-services这个RoleBinding绑定至services-admin角色之后,kube-user1用户拥有管理testing名称空间中的Service资源的所有权限。另外需要注意的是,虽然RoleBinding不能跨名称空间引用Role资源,但主体中的用户账号、用户组和服务账号却不受名称空间的限制,因此,管理员可为一个主体通过不同的RoleBinding资源绑定多个名称空间中的角色。
RoleBinding的配置中主要包含两个嵌套的字段subjects和roleRef,其中,subjects的值是一个对象列表,用于给出要绑定的主体,而roleRef的值是单个对象,用于指定要绑定的Role或ClusterRole资源。subjects字段的可嵌套字段具体如下。
·apiGroup
·kind
·name
·namespace
roleRef的可嵌套字段具体如下。
·apiGroup
·kind
·name
Role和RoleBinding是名称空间级别的资源,它们仅能用于完成单个名称空间内的访问控制,此时若要赋予某主体多个名称空间中的访问权限,就不得不逐个名称空间地进行。另外还有一些资源其本身并不属于名称空间(如PersistentVolume、NameSpace和Node等),甚至还有一些非资源型的URL路径(如/healthz等),对此类资源的管理显然无法在名称空间级别完成,此时就需要用到另外两个集群级别的资源类型ClusterRole和ClusterRoleBinding。
1.4.3 ClusterRole和ClusterRoleBinding
集群级别的角色资源ClusterRole资源除了能够管理与Role资源一样的许可权限之外,还可以用于集群级组件的授权,配置方式及其在rules字段中可内嵌的字段也与Role资源类似。下面的配置清单示例中定义了ClusterRole资源nodes-reader,它拥有访问集群的节点信息的权限:
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: nodes-reader rules: - apiGroups: [""] resources: ["nodes"] verbs: ["get", "watch", "list"]
ClusterRole是集群级别的资源,它不属于名称空间,故在此处其配置不应该使用metadata.namespace字段,这也可以通过获取nodes-reader的状态信息来进行验证。kube-user1用户此前绑定的pods-reader和services-admin角色属于名称空间,它们无法给予此用户访问集群级别nodes资源的权限。
RoleBinding也能够将主体绑定至ClusterRole资源之上,但仅能赋予用户访问Role-Binding资源本身所在的名称空间之内可由ClusterRole赋予的权限,例如,在ClusterRole具有访问所有名称空间的ConfigMap资源权限时,通过testing名称空间的RoleBinding将其绑定至kube-user1用户,则kube-user1用户就具有了访问testing名称空间中的ConfigMap资源的权限,但不能访问其他名称空间中的ConfigMap资源。不过,若借助ClusterRoleBinding进行绑定,则kube-user1就具有了所有相关名称空间中的资源的访问权限,如图10-12所示。

图10-12 RoleBinding与ClusterRoleBinding
因此,一种常见的做法是集群管理员在集群范围内预先定义好一组访问名称空间级别资源权限的ClusterRole资源,而后在多个名称空间中多次通过RoleBinding引用它们,从而让用户分别具有不同名称空间上的资源的相应访问权限,完成名称空间级别权限的快速授予。当然,如果通过ClusterRoleBinding引用这类的ClusterRole,则相应的用户即拥有了在所有相关名称空间上的权限。
集群级别的资源nodes、persistentvolumes等资源,以及非资源型的URL不属于名称空间级别,故此通过RoleBinding绑定至用户时无法完成访问授权。事实上,所有的非名称空间级别的资源都无法通过RoleBinding绑定至用户并赋予用户相关的权限,这些是属于ClusterRoleBinding的功能。
另外,除了名称空间及集群级别的资源之外,Kubernetes还有着/api、/apis、/healthz、/swaggerapi和/version等非资源型URL,对这些URL的访问也必须事先获得相关的权限。同集群级别的资源一样,它们也只能定义在ClusterRole中,且需要基于ClusterRoleBinding进行授权。不过,对此类资源的读取权限已经由系统默认的名称同为system:discovery的ClusterRole和ClusterRoleBinding两个资源自动设定。下面的命令显示了system:discovery ClusterRole的相关信息:
~]$ kubectl get clusterrole system:discovery -o yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: system:discovery … rules: - nonResourceURLs: - /api - /api/* - /apis - /apis/* - /healthz - /swagger-2.0.0.pb-v1 - /swagger.json - /swaggerapi - /swaggerapi/* - /version verbs: - get
nonResourceURLs字段给出了相关的URL列表(不同版本的Kubernetes系统上的显示可能略有区别),允许的访问权限仅有“get”一个。引用了此资源的ClusterRoleBinding的相关信息如下面的命令及其结果所示:
~]$ kubectl get clusterrolebindings system:discovery -o yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: system:discovery … roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:discovery subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: system:authenticated - apiGroup: rbac.authorization.k8s.io kind: Group name: system:unauthenticated
由命令的输出结果可知,它绑定了system:authenticated和system:unauthencated两个组,这囊括了所有的用户账号,因此所有用户默认均有权限请求读取这些资源,任何发往API Server的此类端点读取请求都会得到响应。定义其他类型的访问权限,其方法可参照system:discovery这个ClusterRole资源进行。例如,下面的ClusterRole资源示例定义了对非资源型URL路径/healthz的读写访问权限:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: healthz-admin rules: - nonResourceURLs: - /healthz verbs: - get - create
另外,非资源型URL的授权规则与资源权限的授权规则可定义在同一个ClusterRole中,它们同属于rules字段中的对象。
1.4.4 聚合型ClusterRole
Kubernetes自1.9版本开始支持在rules字段中嵌套aggregationRule字段来整合其他的ClusterRole对象的规则,这种类型的ClusterRole的权限受控于控制器,它们由所有被标签选择器匹配到的用于聚合的ClusterRole的授权规则合并生成。下面是一个示例,它定义了一个标签选择器用于挑选匹配的ClusterRole:
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: monitoring aggregationRule: clusterRoleSelectors: - matchLabels: rbac.example.com/aggregate-to-monitoring: "true" rules: []
任何能够被示例中的资源的标签选择器匹配到的ClusterRole的相关规则都将一同合并为它的授权规则,后续新增的ClusterRole资源亦是如此。因此,聚合型ClusterRole的规则会随着标签选择器的匹配结果而动态变化。下面即是一个能匹配到此聚合型ClusterRole的另一个ClusterRole的示例:
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: monitoring-endpoints labels: rbac.example.com/aggregate-to-monitoring: "true" # These rules will be added to the "monitoring" role. rules: - apiGroups: [""] Resources: ["services", "endpoints", "pods"] verbs: ["get", "list", "watch"]
创建这两个资源,而后查看聚合型ClusterRole资源monitoring的相关权限信息,由下面的命令结果可知,它所拥有的权限包含了ClusterRole资源monitoring-endpoints的所有授权:
~]$ kubectl create -f monitoring.yaml -f monitoring-endpoints.yaml ~]$ kubectl get clusterrole monitoring -o yaml aggregationRule: clusterRoleSelectors: - matchLabels: rbac.example.com/aggregate-to-monitoring: "true" apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: monitoring … rules: - apiGroups: - "" resources: - services - endpoints - pods verbs: - get - list - watch
事实上,Kubernetes系统上面向用户的内建ClusterRole admin和edit也是聚合型Cluster-Role,因为这可以使得默认角色中包含自定义资源的相关规则,例如,由CustomResource-Definitions或Aggregated API服务器提供的规则等。
1.4.5 面向用户的内建ClusterRole
API Server内建了一组默认的ClusterRole和ClusterRoleBinding以预留系统使用,其中大多数都以“system:”为前缀。另外还有一些非以“system:”为前缀的默认的Role资源,它们是为面向用户的需求而设计的,包括超级用户角色(cluster-admin)、用于授权集群级别权限的ClusterRoleBinding(cluster-status)以及授予特定名称空间级别权限的RoleBinding(admin、edit和view),如图10-13所示。掌握这些默认的内建ClusterRole对后期按需创建用户并快速配置权限至关重要。
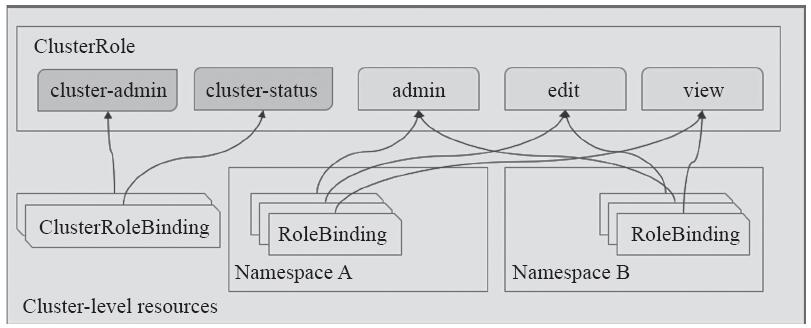
图10-13 内建的面向用户的ClusterRole
内建的ClusterRole资源cluster-admin拥有管理集群所有资源的权限,它基于同名的ClusterRoleBinding资源绑定到了“system:masters”组上,这意味着所有隶属于此组的用户都将具有集群的超级管理权限。kubeadm安装设定集群时自动创建的配置文件/etc/kubernetes/admin.conf中定义的用户kubernetes-admin使用证书文件/etc/kubernetes/pki/piserver- kubelet-client.crt向API Server进行验证。而此证书的Subject信息为“/O=system:masters/CN=kubernetes-admin”,进行认证时,CN的值可作为用户名使用,而O的值将作为用户所属组名使用,因此,kubernetes-admin具有集群管理权限。
于是,为Kubernetes集群额外自定义超级管理员的方法至少具有两种:一种是创建用户证书,其Subject中O的值为“system:masters”,另一种是创建ClusterRoleBinding将用户绑定至cluster-admin之上。其具体的实现方法均可参照1.4.4节和本节中的内容略加变通而实现,cluster-status的使用方法与此类同,有所区别的仅在于权限本身。
另外,在多租户、多项目或多环境等使用场景中,用户通常应该获取名称空间级别绝大多数资源的管理、只读或编辑权限,这类权限的快速授予可通过在指定的名称空间中创建RoleBinding资源引用内建的ClusterRole资源admin、view或edit来进行。例如,在名称空间dev中创建一个RoleBinding资源,它将引用admin,并绑定至kube-user1,使得此用户具有管理dev名称空间中除了名称空间本身及资源配额之外的所有资源的权限:
~]$ kubectl create rolebinding dev-admin --clusterrole=admin --user=kube-user1 -n dev
而后切换至kube-user1用户在dev中创建一个资源,并查看相关的信息进行访问测试,如下面的命令所示:
~]$ kubectl create deployment myapp-deploy --image=ikubernetes/myapp:v1 -n dev deployment.extensions "myapp-deploy" created ~]$ kubectl get all -n dev ……
如果需要授予的是编辑或只读权限,则仅需要将创建RoleBinding时引用的ClusterRole相应地修改为edit或view即可。表10-1总结了典型的面向用户的内建ClusterRole及其功用。
表10-1 面向用户的内建ClusterRole资源

1.4.6 其他的内建ClusterRole和ClusterRoleBinding
API Server会创建一组默认的ClusterRole和ClusterRoleBinding,大多数都以“system:”为前缀,被系统基础架构所使用,修改这些资源将会导致集群功能不正常。例如,如果修改了为kubelet赋权的“system:node”这一ClusterRole,则将会导致kubelet无法工作。所有默认的ClusterRole和ClusterRoleBinding都打了标签“kubernetes.io/bootstrapping=rbac-defaults”。
每次启动时,API Server都会自动为默认的ClusterRole重新赋予缺失的权限,以及为默认的ClusterRoleBinding绑定缺失的Subject。这种机制给了集群从意外修改中自动恢复的能力,以及升级版本后,自动将ClusterRole和ClusterRoleBinding升级到满足新版本需求的能力。
提示 必要时,在默认的ClusterRole或ClusterRoleBinding上设置annnotation中“rbac.authorization.kubernetes.io/autoupdate“属性的值为“false”即可禁止此种自动恢复功能。
Kubernetes内建的其他ClusterRole和ClusterRoleBinding还有很多,它们绝大多数都是用于系统本身的诸多组件结合RBAC获得最小化但完整的资源访问授权。它们大体可分为专用于核心的组件、附加的组件、资源发现及controller-manager运行核心控制循环(control loop)等几个类型,如system:kube-sheduler、system:kube-controller-manager、system:node、system:node-proxier和system:kube-dns等,大多数都可以做到见名知义,这里不再逐一给出说明。
1.5 Kubernetes Dashboard
Dashboard是Kubernetes的Web GUI,可用于在Kubernetes集群上部署容器化应用、应用排障、管理集群本身及其附加的资源等。它常被管理员用于集群及应用速览、创建或修改单个资源(如Deployments、Jobs和DaemonSets等),以及扩展Deployment、启动滚动更新、重启Pod或使用部署向导部署一个新应用等。
注意 Dashboard依赖于Heapster或Metrics Server完成指标数据的采集和可视化。
Dashboard的认证和授权均可由Kubernetes集群实现,它自身仅是一个代理,所有的相关操作都将发给API Server进行,而非由Dashboard自行完成。目前它支持使用的认证方式有承载令牌(bear token)和kubeconfig两种,在访问之前需要准备好相应的认证凭证。
1.5.1 部署HTTPS通信的Dashboard
Dashboard 1.7(不含)之前的版本在部署时直接赋予了管理权限,这种方式可能存在安全风险,因此,1.7及之后的版本默认在部署时仅定义了运行Dashboard所需要的最小权限,仅能够在Master主机上通过“kubectl proxy”命令创建代理后于本机进行访问,它默认禁止了来自于其他任何主机的访问请求。若要绕过“kubectl proxy”直接访问Dashboard,则需要在部署时提供证书以便与客户端进行通信时建立一个安全的HTTPS连接。证书既可由公信CA颁发,也可自行使用openssl或cfssl一类的工具来创建。
部署Dashboard时会从Secrets对象中加载所需要的私钥和证书文件,需要事先准备好相关的私钥、证书和Secrets对象。需要注意的是,下面的命令需要以管理员的身份在Master节点上运行,否则将无法访问到ca.key文件:
~]# (umask 077; openssl genrsa -out dashboard.key 2048) ~]# openssl req -new -key dashboard.key -out dashboard.csr -subj "/O=iLinux/CN=dashboard" ~]# openssl x509 -req -in dashboard.csr -CA /etc/kubernetes/pki/ca.crt \ -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out dashboard.crt -days 3650
接下来,基于生成的私钥和证书文件创建名为kubernetes-dashboard-certs的Opaque类型的Secret对象,其键名分别为dashboard.key和dashboard.crt:
~]$ kubectl create secret generic kubernetes-dashboard-certs \ -n kube-system --from-file=dashboard.crt=./dashboard.crt \ --from-file=dashboard.key=./dashboard.key -n kube-system
Secret对象准备完成后即可部署Dashboard。若无其他自定义部署的需要,可直接基于在线资源配置清单。不过,资源清单中也创建了Secrets对象,因此,它可能会发出警告信息。另外,默认创建的Service对象类型为ClusterIP,它仅能在Pod客户端中访问,若需在集群外通过浏览器访问Dashboard,则需要修改其类型为NodePort再进行创建,或者在创建后通过修改命令进行设定。这里采取直接在线创建,并修改其Service对象kubernetes-dashboard的类型的方式:
~]$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/ src/deploy/recommended/kubernetes-dashboard.yaml ~]$ kubectl patch svc kubernetes-dashboard -p '{"spec":{"type":"NodePort"}}' -n kube-system
确认其使用的NodePort之后便可在集群外通过浏览器进行访问:
~]$ kubectl get svc kubernetes-dashboard -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes-dashboard NodePort 1.11.145.88 <none> 443:31999/TCP 2h
图10-14即为其默认显示的登录页面,支持的认证方式为kubeconfig和token(令牌)两种。
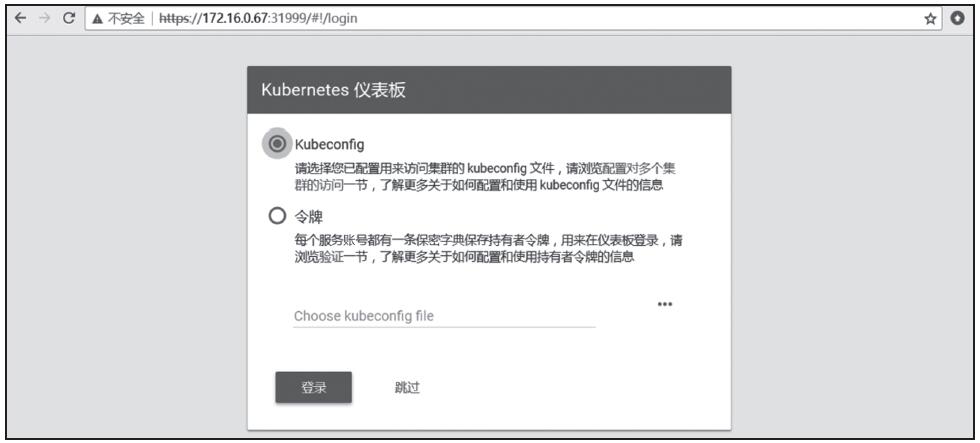
图10-14 Dashboard认证界面
Dashboard是运行于Pod对象中的应用,其连接API Server的账户应为ServiceAccount类型,因此,用户在登录界面提供的用户账号须得是此类账户,而且访问权限也取决于kubeconfig或token认证时的ServiceAccount用户的权限。ServiceAccount的集群资源访问权限取决于它绑定的角色或集群角色,例如,为登录的用户授权集群级别的管理权限时可直接绑定内建的集群角色cluster-admin,授权名称空间级别的管理权限时,可直接绑定内建的集群角色admin。当然,也可以直接自定义RBAC的角色或集群角色,并进行绑定授权,例如集群级别的只读权限或名称空间的只读权限。
1.5.2 配置token认证
集群级别的管理操作依赖于集群管理员权限,例如,管理持久存储卷和名称空间等资源,内建的cluster-admin集群角色拥有相关的全部权限,创建ServiceAccount并将其绑定其上即可完成集群管理员授权。而用户通过相应的ServiceAccount的token信息完成Dashboard认证也就能扮演起Dashboard接口上的集群管理员角色。例如,下面创建一个名为dashboard-admin的ServiceAccount,并完成集群角色绑定:
~]$ kubectl create serviceaccount dashboard-admin -n kube-system ~]$ kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin \ --serviceaccount=kube-system:dashboard-admin
创建ServiceAccount对象时,它会自动为用户生成用于认证的token信息,这一点可以从与其相关的Secrets对象上获取:
~]$ ADMIN_SECRET=$(kubectl -n kube-system get secret | awk '/^dashboard-admin/{print $1}') ~]$ kubectl describe secrets $ADMIN_SECRET -n kube-system kube-system Name: dashboard-admin-token-jfcd6 Namespace: kube-system …… token: eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZ pY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrd WJlLXN5c3RlbSIsImt1YmVyb……
对上面获取到的token在登录界面选择令牌认证方式,并键入token令牌即要登录的Dashboard,其效果如图10-15所示。
上面认证时用到的令牌将采用base64的编码格式,且登录时需要将原内容贴入文本框,存储及操作都有其不便之处,建议用户将它存入kubeconfig配置文件中,通过kubeconfig的认证方式进行登录。
1.5.3 配置kubeconfig认证
kubeconfig是认证信息承载工具,它能够存入私钥和证书,或者认证令牌等作为用户的认证配置文件。为了说明如何配置一个仅具有特定名称空间管理权限的登录账号,这里再次创建一个新的ServiceAccount用于管理默认的default名称空间,并将之绑定于admin集群角色,其操作过程与1.5.2节的方式相似:
~]$ kubectl create serviceaccount def-ns-admin -n default ~]$ kubectl create rolebinding def-ns-admin --clusterrole=admin \ --serviceaccount=default:def-ns-admin
图10-15 Dashboard主面板
下面分步骤说明如何创建所需的kubeconfig文件。第一步,初始化集群信息,提供API Server的URL,以及验证API Server证书所用到的CA证书等。
~]$ kubectl config set-cluster kubernetes --embed-certs=true --server="https:// 172.16.0.70:6443" \ --certificate-authority=/etc/kubernetes/pki/ca.crt --kubeconfig=./def-ns-admin. kubeconfig
第二步,获取def-ns-admin的token,并将其作为认证信息。由于直接得到的token为base64编码格式,因此,下面使用了“base64-d”命令将其解码还原:
~]$ DEFNS_ADMIN_SECRET=$(kubectl -n default get secret | awk '/^def-ns-admin /{print $1}')
~]$ DEFNS_ADMIN_TOKEN=$(kubectl -n default get secret ${DEF_NS_ADMIN_SECRET} \
-o jsonpath={.data.token}|base64 -d)
~]$ kubectl config set-credentials def-ns-admin --token=${DEFNS_ADMIN_TOKEN} \
--kubeconfig=./defns-admin.kubeconfig
第三步,设置context列表,定义一个名为def-ns-admin的context:
~]$ kubectl config set-context def-ns-admin --cluster=kubernetes \ --user=defns-admin --kubeconfig=./defns-admin.kubeconfig
最后指定要使用的context为前面定义的名为def-ns-admin的context:
~]$ kubectl config use-context def-ns-admin --kubeconfig=./defns-admin.kubeconfig
到此为止,一个用于Dashboard登录认证的default名称空间的管理员账号配置文件已经设置完成,将文件复制到远程客户端上即可用于登录认证。
配置token认证和kubeconfig认证时创建ServiceAccount和完成集群角色的绑定以及角色绑定的过程也可以使用资源配置清单文件来实现,相关的文件可在本篇的代码清单目录中获得,分别为dashboard-admin.yaml和def-ns-admin.yaml,可用它们取代前面相关的创建命令。关于Dashboard的使用这里就不再多做介绍了,读者根据界面提示信息很快就能掌握共用法。
1.6 准入控制器与应用示例
在经由认证插件和授权插件分别完成身份认证和权限检查之后,准入控制器将拦截那些创建、更新和删除相关的操作请求以强制实现控制器中定义的功能,包括执行对象的语义验证、设置缺失字段的默认值、限制所有容器使用的镜像文件必须来自某个特定的Registry、检查Pod对象的资源需求是否超出了指定的限制范围等。
但是准入控制器的相关代码必须要由管理员编译进kube-apiserver中才能使用,实现方式缺乏灵活性。于是,Kubernetes自1.7版本引入了Initializers和External Admission Webhooks来尝试突破此限制,而且自1.9版本起,External Admission Webhooks又被分为Mutating-AdmissionWebhook和ValidatingAdmissionWebhook两种类型,分别用于在API中执行对象配置的“变异”和“验证”操作。在具体的代码实现上,一个准入控制器可以是“验证”型、“变异”型或兼具此两项功能。变异控制器可以修改他们许可的对象,而验证控制器则一般不会。
在具体运行时,准入控制可分为两个阶段,第一个阶段串行运行各变异型控制器,第二个阶段串行运行各验证型控制器,在此过程中,一旦任一阶段中的任何控制器拒绝请求,则立即拒绝整个请求,并向用户返回错误。
1.6.1 LimitRange资源与LimitRanger准入控制器
虽然用户可以为容器指定资源需求及资源限制,但未予指定资源限制属性的容器应用很有可能因故吞掉所在工作节点上的所有可用计算资源,因此妥当的做法是使用LimitRange资源在每个名称空间中为每个容器指定最小及最大计算资源用量,甚至是设置默认的计算资源需求和计算资源限制。在名称空间上定义了LimitRange对象之后,客户端提交创建或修改的资源对象将受到LimitRanger控制器的检查,任何违反LimitRange对象定义的资源最大用量的请求将被直接拒绝。
LimitRange资源支持限制容器、Pod和PersistentVolumeClaim三种资源对象的系统资源用量,其中Pod和容器主要用于定义可用的CPU和内存资源范围,而PersistentVolume-Claim则主要定义存储空间的限制范围。下面的配置清单以容器的CPU资源为例,default用于定义默认的资源限制,defaultRequest定义默认的资源需求,min定义最小的资源用量,而最大的资源用量既可以使用max给出固定值,也可以使用maxLimitRequestRatio设定为最小用量的指定倍数:
apiVersion: v1 kind: LimitRange metadata: name: cpu-limit-range spec: limits: - default: cpu: 1000m defaultRequest: cpu: 1000m min: cpu: 500m max: cpu: 2000m maxLimitRequestRatio: cpu: 4 type: Container
将配置清单中的资源创建于集群上的default名称空间中,而后即可使用describe命令查看相关资源的生效结果。创建不同的Pod对象对默认值、最小资源限制及最大资源限制分别进行测试以验证其限制机制。
首先,创建一个仅包含一个容器且没有默认系统资源需求和限制的Pod对象:
~]$ kubectl run limit-pod1--image=ikubernetes/myapp:v1 --restart=Never
Pod对象limit-pod1的详细信息中,容器状态信息段中,CPU资源被默认设定为如下配置,这正好符合了LimitRange对象中定义的默认值:
Limits: cpu: 1 Requests: cpu: 1
若Pod对象设定的系统资源需求量小于LimitRange中的最小用量限制,则会触发LimitRanger准入控制器拒绝相关的请求:
~]$ kubectl run limit-pod2 --image=ikubernetes/myapp:v1 \ --restart=Never --requests='cpu=400m' Error from server (Forbidden): pods "limit-pod4" is forbidden: minimum cpu usage per Container is 500m, but request is 400m.
若Pod对象设定的系统资源限制量大于LimitRange中的最大用量限制,则一样会触发LimitRanger准入控制器拒绝相关的请求:
~]$ kubectl run limit-pod3 --image=ikubernetes/myapp:v1 --restart=Never --limits= 'cpu=3000m' Error from server (Forbidden): pods "limit-pod2" is forbidden: maximum cpu usage per Container is 2, but limit is 3.
事实上,在LimitRange对象中设置的默认的资源需求和资源限制,同最小资源用量及最大资源用量限制能够组合出多种不同的情形,不同组合场景下真正生效的结果也会存在不小的差异。另外,内存资源及PVC资源限制的实现与CPU资源大同小异,鉴于篇幅有限,这部分就留待读者自行验证了。
1.6.2 ResourceQuota资源与准入控制器
尽管LimitRange资源能限制单个容器、Pod及PVC等相关计算资源或存储资源的用量,但用户依然可以创建数量众多的此类资源对象进而侵占所有的系统资源。于是,Kubernetes提供了ResourceQuota资源用于定义名称空间的对象数量或系统资源配额,它支持限制每种资源类型的对象总数,以及所有对象所能消耗的计算资源及存储资源总量等。ResourceQuota准入控制器负责观察传入的请求,并确保它没有违反相应名称空间中ResourceQuota对象定义的任何约束。
于是,管理员可为每个名称空间分别创建一个ResourceQuota对象,随后,用户在名称空间中创建资源对象,ResourceQuota准入控制器将跟踪使用情况以确保它不超过相应ResourceQuota对象中定义的系统资源限制。用户创建或更新资源的操作违反配额约束将导致请求失败,API Server以HTTP状态代码“403FORBIDDEN”作为响应,并显示一条消息以提示可能违反的约束。不过,在名称空间上启用了CPU和内存等系统资源的配额后,用户创建Pod对象时必须指定资源需求或资源限制,否则,会触发ResourceQuota准入控制器拒绝执行相应的操作。
ResourceQuota对象可限制指定名称空间中非终止状态的所有Pod对象的计算资源需求及计算资源限制总量。
·cpu或requests.cpu:CPU资源需求的总量限额。
·memory或requests.cpu:内存资源需求的总量限额。
·limits.cpu:CPU资源限制的总量限额。
·limits.memory:内存资源限制的总量限额。
ResourceQuota对象支持限制特定名称空间中可以使用的PVC数量和这些PVC资源的空间大小总量,以及特定名称空间中可在指定的StorageClass上使用的PVC数量和这些PVC资源的总数:
·requests.storage:所有PVC存储需求的总量限额。
·persistentvolumeclaims:可以创建的PVC总数。
·<s torage-class-name>.storageclass.storage.k8s.io/requests.storage:指定存储类上可使用的所有PVC存储需求的总量限额。
·<s torage-class-name>.storageclass.storage.k8s.io/persistentvolumeclaims:指定存储类上可使用的PVC总数。
·requests.ephemeral-storage:所有Pod可用的本地临时存储需求的总量。
·limits.ephemeral-storage:所有Pod可用的本地临时存储限制的总量。
在1.9版本之前,ResourceQuota支持在名称空间级别的有限的几种资源集上设定对象计数配额,如Pods、Services和ConfigMAPs等,而自1.9版本起支持以“count/
下面的配置清单示例定义了一个ResourceQuota资源对象,它配置了计算资源、存储资源及对象计数几个维度的限额:
apiVersion: v1 kind: ResourceQuota metadata: name: quota-example spec: hard: pods: "5" requests.cpu: "1" requests.memory: 1Gi limits.cpu: "2" limits.memory: 2Gi count/deployments.apps: "1" count/deployments.extensions: "1" persistentvolumeclaims: "2"
创建完成后,describe命令可以打印其限额的生效情况,例如,将上面的ResourceQuota对象创建于test名称空间中,其打印结果如下所示:
~]$ kubectl describe quota quota-example -n test Name: quota-example Namespace: test Resource Used Hard -------- ---- ---- count/deployments.apps 0 1 count/deployments.extensions 0 1 limits.cpu 0 2 limits.memory 0 2Gi persistentvolumeclaims 0 2 pods 0 5 requests.cpu 0 1 requests.memory 0 1Gi
在test名称空间中创建Deployment等对象即可进行配额测试,例如,下面的命令创建了一个有着3个Pod副本的Deployment对象myapp-deploy:
~]$ kubectl run myapp-deploy --image=ikubernetes/myapp:v1 --replicas=3 \ --namespace=test --requests='cpu=200m,memory=256Mi' --limits='cpu=500m,memory=256Mi'
创建完成后,test名称空间上的ResourceQuota对象quota-example的各配置属性也相应地变成了如下状态:
Resource Used Hard -------- ---- ---- count/deployments.apps 1 2 count/deployments.extensions 1 2 limits.cpu 1200m 2 limits.memory 768Mi 2Gi persistentvolumeclaims 0 2 pods 3 5 requests.cpu 500m 1 requests.memory 640Mi 1Gi
此时,再扩展myapp-deploy的规模则会很快遇到某一项配额的限制而导致扩展受阻。由分析可知,将Pod副本数量扩展至5个就会达到limits.cpu资源上限而导致第5个扩展失败。读者可自行扩展并测试其结果。
需要注意的是,资源配额仅对那些在ResourceQuota对象创建之后生成的对象有效,对已经存在的对象不会产生任何限制。而且,一旦启用了计算资源需求和计算资源限制配额,那么创建的任何Pod对象都必须设置此两类属性,否则Pod对象的创建将会被相应的ResourceQuota对象所阻止。无须手动为每个Pod对象设置此两类属性时,可以使用LimitRange对象为其设置默认值。
每个ResourceQuota对象上还支持定义一组适用范围(scope),用于定义其配额仅生效于这组适用范围交集内的对象,目前可用的适用范围包括Terminating、NotTerminating、BestEffort和NotBestEffort,具体说明如下。
·Terminating:匹配.spec.activeDeadlineSeconds的属性值大于等于0的所有Pod对象。
·NotTerminating:匹配.spec.activeDeadlineSeconds的属性值为空的所有Pod对象。
·BestEffort:匹配所有位于BestEffort QoS类别的Pod对象。
·NotBestEffort:匹配所有非BestEffort QoS类别的Pod对象。
另外,自1.8版本起,管理员即可以设置不同的优先级类别(PriorityClass)来创建Pod对象,而自1.11版本起,Kubernetes开始支持对每个PriorityClass对象分别设定资源限额,管理员可以使用scopeSelector字段,从而根据Pod对象的优先级控制Pod资源对系统资源的消耗。
1.6.3 PodSecurityPolicy
PodSecurityPolicy(简称PSP)是集群级别的资源类型,用于控制用户在配置Pod资源的期望状态时可以设定的特权类的属性,如是否可以使用特权容器、根命名空间和主机文件系统,以及可使用的主机网络和端口、卷类型和Linux Capabilities等。不过,PSP对象定义的策略本身并不会直接发生作用,它们需要经由PodSecurityPolicy准入控制器检查并强制生效。
不过,PSP准入控制器默认是处于未启用状态的,原因是在未创建任何PSP对象的情况下启用此准入控制器将阻止在集群中创建任何Pod对象。不过,PSP资源的API接口(policy/v1beta1/podsecuritypolicy)独立于PSP准入控制器,因此管理员可以事先定义好所需要的Pod安全策略,而后再设置kube-apiserver启用PSP准入控制器。不当的Pod安全策略可能会产生难以预料的副作用,因此请确保所添加的任何PSP对象都经过了充分的测试。
启用PSP准入控制器后若要部署任何Pod对象,则相关的User Account及Service Account必须全部获得了恰当的Pod安全策略授权。以常规用户的身份直接创建Pod对象时,PSP准入控制器将根据账户有权使用的Pod安全策略验证其凭据。若不存在任何策略支持Pod对象安全性要求,则会拒绝相关的创建操作。而基于控制器(如Deployment)创建Pod对象时,Kubernetes会根据服务账户有权使用的Pod安全策略验证Pod的Service Account凭据。若没有策略支持Pod对象的安全性要求,则Pod控制器自身能够成功创建,但Pod对象不会。
事实上,即便是在启用了PSP准入控制器的情况下创建的PSP对象也依然不会发生效用,而是要由授权插件(如RBAC)将“use”操作权限授权给特定的Role或ClusterRole,而后将Use Account或Service Account完成角色绑定才可以。下面简单说明一下设定重要的Pod安全策略,而后启用PSP准入控制器使其生效的方法。
1.设置特权及受限的PSP对象
一般说来,system:masters组内的管理员用户、system:node组内的kubelet,以及kube-system名称空间中的Service Account需要拥有创建各类Pod对象的授权,包括特权Pod对象。因此,首先要创建一个特权PSP,授予相关的管理员权限。一个示例性的配置清单如下:
apiVersion: policy/v1beta1 kind: PodSecurityPolicy metadata: name: privileged annotations: seccomp.security.alpha.kubernetes.io/allowedProfileNames: '*' spec: privileged: true allowPrivilegeEscalation: true allowedCapabilities: - '*' volumes: - '*' hostNetwork: true hostPorts: - min: 0 max: 65535 hostIPC: true hostPID: true runAsUser: rule: 'RunAsAny' seLinux: rule: 'RunAsAny' supplementalGroups: rule: 'RunAsAny' fsGroup: rule: 'RunAsAny'
相应地,经过API Server成功认证的User Account或Service Account多数都应该具有创建非特权Pod对象的授权,因此,它们应该获取受限的安全策略。下面的配置清单定义了一个非特权的安全策略,它禁止了大多数的特权操作:
apiVersion: policy/v1beta1 kind: PodSecurityPolicy metadata: name: restricted annotations: seccomp.security.alpha.kubernetes.io/allowedProfileNames: 'docker/default' apparmor.security.beta.kubernetes.io/allowedProfileNames: 'runtime/default' seccomp.security.alpha.kubernetes.io/defaultProfileName: 'docker/default' apparmor.security.beta.kubernetes.io/defaultProfileName: 'runtime/default' spec: privileged: false # Required to prevent escalations to root. allowPrivilegeEscalation: false # This is redundant with non-root + disallow privilege escalation, # but we can provide it for defense in depth. requiredDropCapabilities: - ALL # Allow core volume types. volumes: - 'configMap' - 'emptyDir' - 'projected' - 'secret' - 'downwardAPI' # Assume that persistentVolumes set up by the cluster admin are safe to use. - 'persistentVolumeClaim' hostNetwork: false hostIPC: false hostPID: false runAsUser: # Require the container to run without root privileges. rule: 'MustRunAsNonRoot' seLinux: # This policy assumes the nodes are using AppArmor rather than SELinux. rule: 'RunAsAny' supplementalGroups: rule: 'MustRunAs' ranges: # Forbid adding the root group. - min: 1 max: 65535 fsGroup: rule: 'MustRunAs' ranges: # Forbid adding the root group. - min: 1 max: 65535 readOnlyRootFilesystem: false
将上述两个配置清单中定义的PSP资源提交并创建于API Server之上,随后便可授权特定的Role或ClusterRole资源通过use进行调用了。
2.创建ClusterRole并完成账户绑定
创建一个ClusterRole对象psp:privileged,授权其可以使用名为privileged的PSP对象,并创建一个ClusterRole对象psp:restricted,授权其可以使用名为restricted的PSP对象,如下面的配置清单所示:
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: psp:restricted rules: - apiGroups: ['policy'] resources: ['podsecuritypolicies'] verbs: ['use'] resourceNames: - restricted --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: psp:privileged rules: - apiGroups: ['policy'] resources: ['podsecuritypolicies'] verbs: ['use'] resourceNames: - privileged
而后创建ClusterRoleBinding对象,将system:masters、system:node和system:serviceaccounts:kube-system组的账户绑定至psp:privileged,让它们拥有管理员权限,并将system:authenticated 组内的账户绑定至psp:restricted,授予它们创建普通Pod对象的权限:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: privileged-psp-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: psp:privileged subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: system:masters - apiGroup: rbac.authorization.k8s.io kind: Group name: system:node - apiGroup: rbac.authorization.k8s.io kind: Group name: system:serviceaccounts:kube-system --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: restricted-psp-user roleRef: kind: ClusterRole name: psp:restricted apiGroup: rbac.authorization.k8s.io subjects: - kind: Group apiGroup: rbac.authorization.k8s.io name: system:authenticated
3.启用PSP准入控制器
待上述步骤完成之后,设置kube-apiserver的--enable-admission-plugins选项,在其列表中添加“PodSecurityPolicy”项目,并重启kube-apiserver便能启用PSP准入控制器。而对于使用kubeadm部署的Kubernetes集群来说,编辑Master节点上的/etc/kubernetes/manifests/kube-apiserver.yaml配置清单,在其--enable-admission-plugins选项后的列表上添加“PodSecurity- Policy”项目,等kube-apiserver相关的Pod对象自动重构完成之后即会启用PSP准入控制器。
随后,创建拥有特权securityContext的Pod资源配置清单,并以经过认证的User Account或Service Account分别创建特权和非特权的Pod对象便能验证Pod安全策略的效果。例如,为前面章节中创建的kube-user1使用Rolebinding对象在test名称空间绑定至名为admin的ClusterRole对象,授予其test名称空间的管理员权限,而后再由其尝试创建下面清单中定义的特权Pod对象:
apiVersion: v1 kind: Pod metadata: name: pod-with-securitycontext spec: containers: - name: busybox image: busybox imagePullPolicy: IfNotPresent command: ["/bin/sh","-c","sleep 86400"] securityContext: privileged: true
将上面的配置清单保存于配置文件中,如pod-test.yaml,而后进行创建测试:
~]$ kubectl apply -f pod-test.yaml -n test Error from server (Forbidden): error when creating "pod-test.yaml": pods "pod-with- securitycontext" is forbidden: unable to validate against any pod security policy: [spec.containers[0].securityContext.privileged: Invalid value: true: Privileged containers are not allowed]
命令结果显示创建操作被PSP定义的策略所拒绝,因为kube-user1用户被归类到system:authenticated组中,因此被关联到了restricted安全策略上。移除配置清单中的security-Context及其嵌套的字段再次执行创建操作即可成功完成,感兴趣的读者可自行测试。另外,读者可按此方式授权特定的用户拥有特定类型的Pod对象创建权限,但策略冲突时可能会导致意料不到的结果,因此任何Pod安全策略在生效之前请务必做到充分测试。
1.7 本篇小结
本篇主要讲解了Kubernetes的认证、授权及准入控制相关的话题,其中重点说明了以下内容。
·Kubernetes系统的认证、授权及准入控制插件的工作流程。
·Service Account资源及其应用方式。
·HTTPS客户端证书认证及其在kubectl和tls bootstrap中的应用。
·Role及RoleBinding的工作机制及应用方式。
·ClusterRole及ClusterRoleBinding的工作机制及其应用方式。
·借助默认的ClusterRole及ClusterRoleBinding实现集群及名称空间级别权限的快速授予。
·Dashboard及其分级权限授予。
·使用LimitRange资源限制名称空间下容器、Pod及PVC对象的系统资源限制。
·使用ResourceQuota设置名称空间的总资源限制。
·使用PodSecurityPolicy设置创建Pod对象的安全策略。
版权声明:如无特殊说明,文章均为本站原创,版权所有,转载需注明本文链接
本文链接:http://www.bianchengvip.com/article/Kubernetes-Security-Authentication-Authorization/