大家好,我是腾意。
自Docker技术诞生以来,采用容器技术用于开发、测试甚至是生产环境的企业或组织与日俱增。然而,将容器技术应用于生产环境时如何确定合适的网络方案依然是亟待解决的最大问题,这也曾是主机虚拟化时代的著名难题之一,它不仅涉及了网络中各组件的互连互通,还需要将容器与不相关的其他容器进行有效隔离以确保其安全性。本篇将主要讲述容器网络模型的进化、Kubernetes的网络模型、常用网络插件以及网络策略等相关的话题。
1.1 Kubernetes网络模型及CNI插件
Docker的传统网络模型在应用至日趋复杂的实际业务场景时必将导致复杂性的几何级数上升,由此,Kubernetes设计了一种网络模型,它要求所有容器都能够通过一个扁平的网络平面直接进行通信(在同一IP网络中),无论它们是否运行于集群中的同一节点。不过,在Kubernetes集群中,IP地址分配是以Pod对象为单位,而非容器,同一Pod内的所有容器共享同一网络名称空间。
1.1.1 Docker容器的网络模型
Docker容器网络的原始模型主要有三种:Bridge(桥接)、Host(主机)及Container(容器)。Bridge模型借助于虚拟网桥设备为容器建立网络连接,Host模型则设定容器直接共享使用节点主机的网络名称空间,而Container模型则是指多个容器共享同一个网络名称空间,从而彼此之间能够以本地通信的方式建立连接。
Docker守护进程首次启动时,它会在当前节点上创建一个名为docker0的桥设备,并默认配置其使用172.17.0.0/16网络,该网络是Bridge模型的一种实现,也是创建Docker容器时默认使用的网络模型。如图11-1所示,创建Docker容器时,默认有四种网络可供选择使用,从而表现出了四种不同类型的容器,具体如下。
·Closed container(封闭式容器):此类容器使用“None”网络,它们没有对外通信的网络接口,而是仅具有I/O接口,通常仅用于不需要网络的后端作业处理场景。
·Bridged container(桥接式容器):此类容器使用“Bridge”模型的网络,对于每个网络接口,容器引擎都会为每个容器创建一对(两个)虚拟以太网设备,一个配置为容器的接口设备,另一个则在节点主机上接入指定的虚拟网桥设备(默认为docker0)。
·Open container(开放式容器):此类容器使用“Host”模型的网络,它们共享使用Docker主机的网络及其接口。
·Joined container(联盟式容器):此类容器共享使用某个已存在的容器的网络名称空间,即共享并使用指定的容器的网络及其接口。
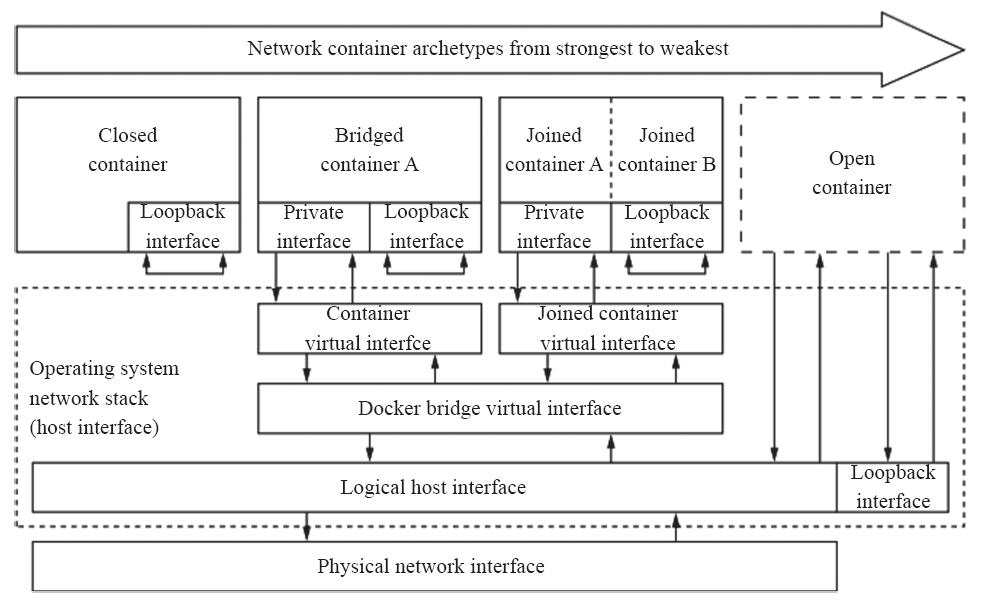
图11-1 Docker容器网络
上述的容器间通信仅描述了同一节点上的容器间通信的可用方案,这应该也是Docker设计者早期最为关注的容器通信目标。然而,在生产环境中使用容器技术时,跨节点的容器间通信反倒更为常见,可根据网络类型将其实现方式简单划分为如下几种。
·为各Docker节点创建物理网络桥接接口,设定各节点上的容器使用此桥设备从而直接暴露于物理网络中。
·配置各节点上的容器直接共享使用其节点的网络名称空间。
·将容器接入指定的桥设备,如docker0,并设置其借助NAT机制进行通信。
第三种方案是较为流行且默认的解决方案。不过,此种方案的IPAM(IP Address Management)是基于容器主机本地范围进行的,每个节点上的容器都将从同一个网络172.17.0.0/16中获取IP地址,这就意味着不同Docker主机上的容器可能会使用相同的地址,因此它们也就无法直接通信。
解决此问题的通行方式是为NAT。所有接入到此桥设备上的容器均会被NAT隐藏,它们发往Docker主机外部的所有流量都会在执行过源地址转换后发出,并且默认是无法直接接收节点之外的其他主机发来的请求的。若要接入Docker主机外部的流量,则需要事先通过目标地址转换甚至额外的端口转换将其暴露于外部网络中,如图11-2所示。
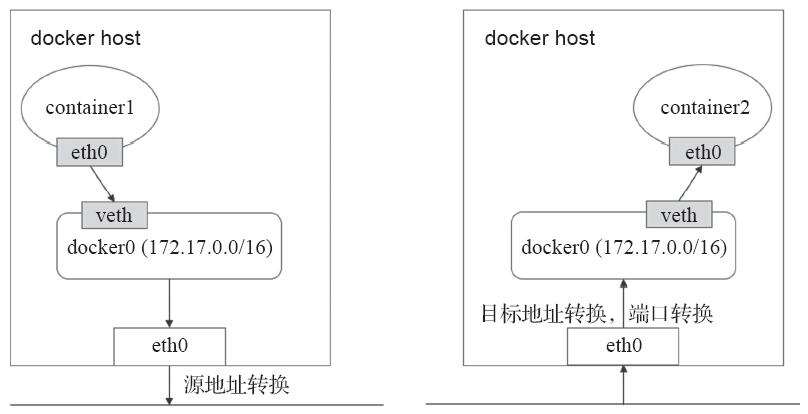
图11-2 跨节点容器间的通信示例图
故此,传统的解决方案中,多节点上的Docker容器间通信依赖于NAT机制转发实现。这种解决方案在网络规模庞大时将变得极为复杂、对系统资源的消耗较大且转发效率低下。此外,docker host的端口也是一种稀缺资源,静态分配和映射极易导致冲突,而动态分配又很容易导致模型的进一步复杂化。
事实上,Docker网络也可借助于第三方解决方案来规避NAT通信模型导致的复杂化问题,后来还发布了CNM(Container Network Model)规范,现在已经被Cisco Contiv、Kuryr、Open Virtual Networking(OVN)、Project Calico、VMware或Weave这些公司和项目所采纳。不过,这种模型被采用时,也就属于了容器编排的范畴。
1.1.2 Kubernetes网络模型
Kubernetes的网络模型主要可用于解决四类通信需求:同一Pod内容器间的通信(Container to Container)、Pod间的通信(Pod to Pod)、Service到Pod间的通信(Service to Pod)以及集群外部与Service之间的通信(external to Service)。
(1)容器间通信
Pod对象内的各容器共享同一网络名称空间,它通常由构建Pod对象的基础架构容器所提供,例如,由pause镜像启动的容器。所有运行于同一个Pod内的容器与同一主机上的多个进程类似,彼此之间可通过lo接口完成交互,如图11-3所示,Pod P内的Container1和Container2之间的通信即为容器间通信。
(2)Pod间通信
各Pod对象需要运行于同一个平面网络中,每个Pod对象拥有一个集群全局唯一的地址并可直接用于与其他Pod进行通信,如图11-3中的Pod P和Pod Q之间的通信。此网络也称为Pod网络。另外,运行Pod的各节点也会通过桥接设备等持有此平面网络中的一个IP地址,如图11-3中的cbr0接口,这就意味着Node到Pod间的通信也可在此网络上直接进行。因此,Pod间的通信或Pod到Node间的通信比较类似于同一IP网络中主机间进行的通信。
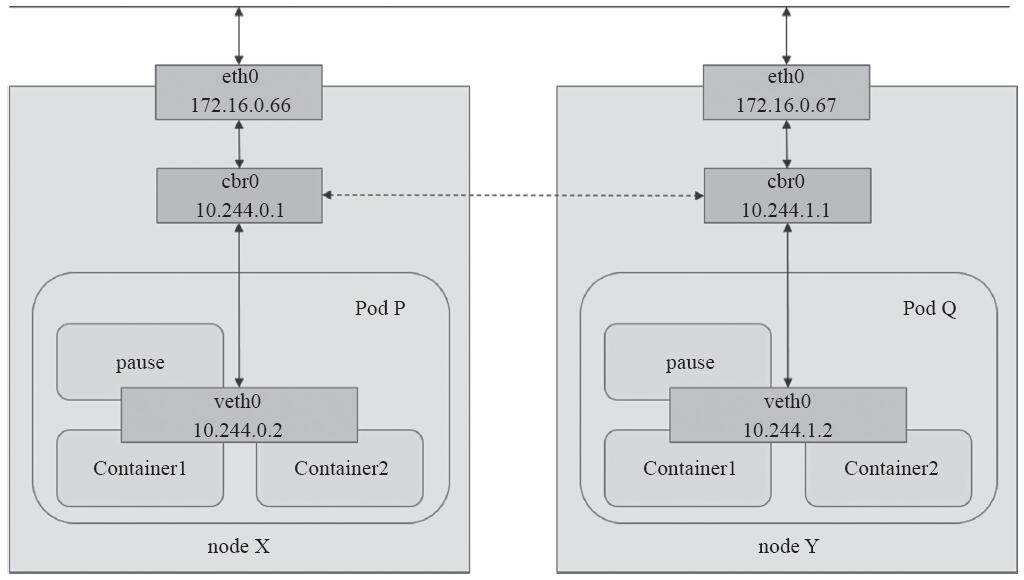
图11-3 Pod网络
此类通信模型中的通信需求也是Kubernetes的各网络插件需要着力解决的问题,它们的实现方式有叠加网络模型和路由网络模型等,流行的解决方案有十数种之多,例如前面使用到的flannel。
(3)Service与Pod间的通信
Service资源的专用网络也称为集群网络(Cluster Network),需要在启动kube-apiserver时经由“--service-cluster-ip-range”选项进行指定,如10.96.0.0/12,而每个Service对象在此网络中均拥一个称为Cluster-IP的固定地址。管理员或用户对Service对象的创建或更改操作由API Server存储完成后触发各节点上的kube-proxy,并根据代理模式的不同将其定义为相应节点上的iptables规则或ipvs规则,借此完成从Service的Cluster-IP与Pod-IP之间的报文转发,如图11-4所示。
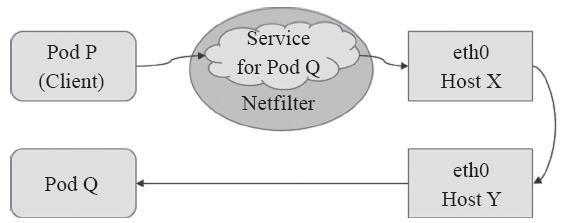
图11-4 Service和Pod
(4)集群外部到Pod对象之间的通信
将集群外部的流量引入到Pod对象的方式有受限于Pod所在的工作节点范围的节点端口(nodePort)和主机网络(hostNetwork)两种,以及工作于集群级别的NodePort或LoadBalancer类型的Service对象。不过,即便是四层代理的模式也要经由两级转发才能到达目标Pod资源:请求流量首先到达外部负载均衡器,由其调度至某个工作节点之上,而后再由工作节点的netfilter(kube-proxy)组件上的规则(iptables或ipvs)调度至某个目标Pod对象。
以上4种通信方法的具体应用方式在前面的章节中已有详细描述,因此这里不再给出更进一步的说明。
1.1.3 Pod网络的实现方式
每个Pod对象内的基础架构容器均使用一个独立的网络名称空间,并共享给同一Pod内的其他容器使用。每个名称空间均有其专用的独立网络协议栈及其相关的网络接口设备。一个网络接口仅能属于一个网络名称空间,于是,运行多个Pod必然要求使用多个网络名称空间,也就需要用到多个网络接口设备。不过,一个易于实现的方案是使用软件实现的伪网络接口及模拟线缆将其连接至物理接口。伪网络接口的实现方案常见的有虚拟网桥、多路复用及硬件交换三种,如图11-5所示。
·虚拟网桥:创建一对虚拟以太网接口(veth),一个接入容器内部,另一个留置于根名称空间内并借助于Linux内核桥接功能或OpenVSwitch(OVS)关联至真实的物理接口。
·多路复用:多路复用可以由一个中间网络设备组成,它暴露了多个虚拟接口,可使用数据包转发规则来控制每个数据包转到的目标接口。MACVLAN为每个虚拟接口配置一个MAC地址并基于此地址完成二层报文收发,而IPVLAN是基于IP地址的并使用单个MAC,从而使其更适合VM。
·硬件交换:现今市面上的大多数NIC都支持单根I/O虚拟化(SR-IOV),它是创建虚拟设备的一种实现方式。每个虚拟设备自身均表现为一个独立的PCI设备,并有着自己的VLAN及与硬件强制关联的QoS。SR-IOV提供了接近硬件级别的性能,但在公共云中通常是不可用的。
大多数情况下,用户希望创建跨越多个L2或L3的逻辑网络子网,这就要借助于叠加封装协议来实现(最常见的是VXLAN,它将叠加流量封装到UDP数据包中)。不过,由于控制平面缺乏标准化,VXLAN可能会引入更高的开销,并且来自不同供应商的多个VXLAN网络通常无法互操作。而Kubernetes还将大量使用iptables和NAT来拦截进入逻辑/虚拟地址的流量并将其路由到适当的物理目的地。
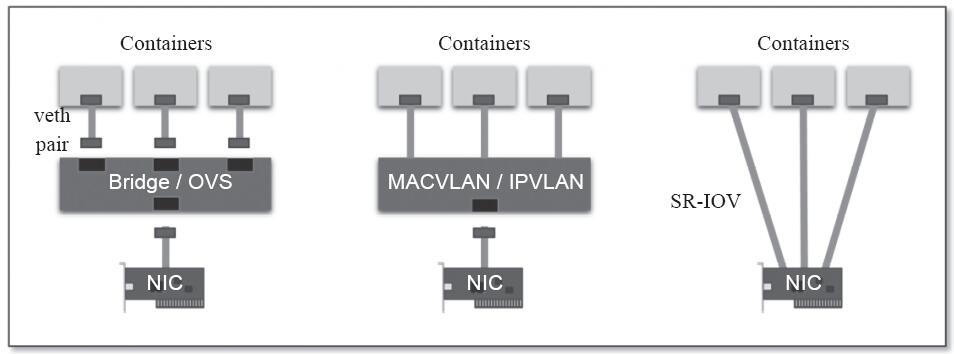
图11-5 虚拟网桥、多路复用及硬件交换
无论上述哪种方式应用于容器环境中,其实现过程都需要大量的操作步骤。不过,目前Kubernetes支持使用CNI插件来编排网络,以实现Pod及集群网络管理功能的自动化。每次Pod被初始化或删除时,kubelet都会调用默认的CNI插件创建一个虚拟设备接口附加到相关的底层网络,为其设置IP地址、路由信息并将其映射到Pod对象的网络名称空间。
配置Pod的网络时,kubelet首先在默认的/etc/cni/net.d/目录中查找CNI JSON配置文件,接着基于type属性到/opt/cni/bin/中查找相关的插件二进制文件,如下面示例中的“portmap”。随后,由CNI插件调用IPAM插件(IP地址管理)来设置每个接口的IP地址,如host-local或dhcp等:
~]$ cat /etc/cni/net.d/10-flannel.conflist { "name": "cbr0", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] }
kubelet基于包含命令参数CNI_ARGS、CNI_COMMAND、CNI_IFNAME、CNI_NETNS、CNI_CONTAINERID、CNI_PATH的环境变量调用CNI插件,并经由stdin流式传输json.conf文件。被调用的插件使用JSON格式的文本信息进行响应,描述操作结果和状态。借助于插件框架,有着熟练的Go编程语言能力的读者,可以轻松开发出自己的CNI插件,或者扩展现有插件。
配置网络接口时,kubelet将Pod对象的名称和名称空间作为CNI_ARGS变量的一部分进行传递(如“K8S_POD_NAMESPACE=default;K8S_POD_NAME=myapp-6d9f48c5d9-n77qp;”)。它可以定义每个Pod对象或Pod网络名称空间的网络配置(例如,将每个网络名称空间放在不同的子网中)。未来的Kubernetes版本将网络视为一等的公民,并将网络配置作为Pod对象或名称空间规范的一部分,就像内存、CPU和存储卷一样。目前,可以使用注解(annotations)来存储配置或记录Pod网络数据/状态。
1.1.4 CNI插件及其常见的实现
Kubernetes设计了网络模型,但将其实现交给了网络插件。于是,各种解决方案不断涌现。为了规范及兼容各种解决方案,CoreOS和Google联合制定了CNI(Container Network Interface)标准,旨在定义容器网络模型规范。它连接了两个组件:容器管理系统和网络插件。它们之间通过JSON格式的文件进行通信,以实现容器的网络功能。具体的工作均由插件来实现,包括创建容器netns、关联网络接口到对应的netns以及为网络接口分配IP等。CNI的基本思想是:容器运行时环境在创建容器时,先创建好网络名称空间(netns),然后调用CNI插件为这个netns配置网络,而后再启动容器内的进程。
CNI本身只是规范,付诸生产还需要有特定的实现。目前,CNI提供的插件分为三类:main、meta和ipam。main一类的插件主要在于实现某种特定的网络功能,例如loopback、bridge、macvlan和ipvlan等;meta一类的插件自身并不提供任何网络实现,而是用于调用其他插件,例如调用flannel;ipam仅用于分配IP地址,而不提供网络实现。
CNI具有很强的扩展性和灵活性,例如,如果用户对某个插件具有额外的需求,则可以通过输入中的args和环境变量CNI_ARGS进行传递,然后在插件中实现自定义的功能,这大大增加了它的扩展性。另外,CNI插件将main和ipam分开,赋予了用户自由组合它们的机制,甚至一个CNI插件也可以直接调用另外一个CNI插件。CNI目前已经是Kubernetes当前推荐的网络方案。常见的CNI网络插件包含如下这些主流的项目。
·Flannel:一个为Kubernetes提供叠加网络的网络插件,它基于Linux TUN/TAP,使用UDP封装IP报文来创建叠加网络,并借助etcd维护网络的分配情况。
·Calico:一个基于BGP的三层网络插件,并且也支持网络策略来实现网络的访问控制;它在每台机器上运行一个vRouter,利用Linux内核来转发网络数据包,并借助iptables实现防火墙等功能。
·Canal:由Flannel和Calico联合发布的一个统一网络插件,提供CNI网络插件,并支持网络策略。
·Weave Net:Weave Net是一个多主机容器的网络方案,支持去中心化的控制平面,在各个host上的wRouter间建立Full Mesh的TCP连接,并通过Gossip来同步控制信息。
·数据平面上,Weave通过UDP封装实现L2Overlay,封装支持两种模式,一种是运行在user space的sleeve mode,另一种是运行在kernal space的fastpath mode。
·Contiv:思科开源的容器网络方案,主要提供基于Policy的网络管理,并与主流容器编排系统集成;Contiv最主要的优势是直接提供了多租户网络,并支持L2(VLAN)、L3(BGP)、Overlay(VXLAN)等。
·OpenContrail:Juniper推出的开源网络虚拟化平台,其商业版本为Contrail。其主要由控制器和vRouter组成,控制器提供虚拟网络的配置、控制和分析功能,vRouter则提供分布式路由,负责虚拟路由器、虚拟网络的建立及数据转发。
·Romana:由Panic Networks于2016年释出的开源项目,旨在借鉴路由汇聚(route aggregation)的思路来解决叠加方案为网络带来的开销。
·NSX-T:由VMware提供,用于定义敏捷SDI(Software-Defined Infrastructure)以构建云原生应用环境;其旨在合并异构端点或技术栈的应用框架和架构,如vSphere、KVM、容器和bare metal等。
·kube-router:kube-router是Kubernetes网络的一体化解决方案,它可取代kube-proxy实现基于ipvs的Service,能为Pod提供网络,支持网络策略以及拥有完美兼容BGP的高级特性。
上述的CNI网络插件在实现方式、传输性能、功能特性等方面存在着不小的差别,部署时,用户需要根据网络环境和业务需要等来选择合适的项目。不过,就目前的统计(https://thenewstack.io )来看,flannel和calico两个项目是最为流行的选择,如图11-6所示。

图11-6 CNI网络插件的采用率统计情况(含多选)
随着Kubernetes的演进,必将涌现出越来越多的CNI插件,它们各具特色,各有优劣。实践中,用户根据实际需要选择合用的方案即可。本篇将介绍flannel和calico两种主流的方案及其部署和应用,不过,另一个非常值得关注的解决方案是kube-router。
1.2 flannel网络插件
各Docker主机在docker0桥上默认使用同一个子网,不同节点的容器很可能会得到相同的地址,于是跨节点的容器间通信会面临地址冲突的问题。另外,即使人为地设定多个节点上的docker0桥使用不同的子网,其报文也会因为在网络中缺乏路由信息而无法准确送达。事实上,各种CNI插件都至少要解决这两类问题。
对于第一个问题,flannel的解决办法是,预留使用一个网络,如10.244.0.0/16,而后自动为每个节点的Docker容器引擎分配一个子网,如10.244.1.0/24和10.244.20/24,并将其分配信息保存于etcd持久存储。对于第二个问题,flannel有着多种不同的处理方法,每一种处理方法也可以称为一种网络模型,或者称为flannel使用的后端。
·VxLAN:Linux内核自3.7.0版本起支持VxLAN,flannel的此种后端意味着使用内核中的VxLAN模块封装报文,这也是flannel较为推荐使用的方式。

图11-7 VxLAN协议报文
·host-gw:即Host GateWay,它通过在节点上创建到达目标容器地址的路由直接完成报文转发,因此这种方式要求各节点本身必须在同一个二层网络中,故该方式不太适用于较大的网络规模(大二层网络除外)。host-gw有着较好的转发性能,且易于设定,推荐对报文转发性能要求较高的场景使用。
·UDP:使用普通UDP报文封装完成隧道转发,其性能较前两种方式要低很多,仅应该在不支持前两种方式的环境中使用。
flannel初创之后的一段时期内,不少环境中的Linux发行版的内核尚且不支持VxLAN,而host-gw模式有着略高的网络技术门槛,故此大多数部署场景只好使用UDP模式,flannel因而不幸地落下性能不好的声名。不过,目前flannel的部署默认后端已经是叠加网络模型VxLAN。另外,除了这三种后端之外,flannel还实验性地支持AliVPC、AWS VPC、Alloc和GCE几种后端。
1.2.1 flannel的配置参数
为了跟踪各子网分配信息等,flannel使用etcd来存储虚拟IP和主机IP之间的映射,各个节点上运行的flanneld守护进程负责监视etcd中的信息并完成报文路由。默认情况下,flannel的配置信息保存于etcd的键名/coreos.com/network/config之下,可以使用etcd服务的客户端工具来设定或修改其可用的相关配置。config的值是一个JSON格式的字典数据结构,它可以使用的键包含以下几个。
1)Network:flannel于全局使用的CIDR格式的IPv4网络,字符串格式,此为必选键,余下的均为可选。
2)SubnetLen:将Network属性指定的IPv4网络基于指定位的掩码切割为供各节点使用的子网,此网络的掩码小于24时(如16),其切割子网时使用的掩码默认为24位。
3)SubnetMin:可用作分配给节点使用的起始子网,默认为切分完成后的第一个子网;字符串格式。
4)SubnetMax:可用作分配给节点使用的最大子网,默认为切分完成后最大的一个子网;字符串格式。
5)Backend:flannel要使用的后端类型,以及后端的相关配置,字典格式;VxLAN、host-gw和UDP后端各有其相关的参数。
例如下面的配置示例中,全局网络为“10.244.0.0/16”,切分子网时用到的掩码长度为24,将相应的子网10.244.0.0/24-10.244.255.0/24分别分配给每一个工作节点使用,选择VxLAN作为使用的后端类型,并监听于8472端口:
{ "Network": "10.244.0.0/16", "SubnetLen": 24, "Backend": { "Type": "VxLAN", "Port": 8472 } }
以上配置信息可直接由flannel保存于etcd存储中,也可交由Kubernetes进行存储。具体使用的方式取决于管理员或部署程序的默认配置。另外,flannel默认使用VxLAN后端,但VxLAN direct routing和host-gw却有着更好的性能表现。
1.2.2 VxLAN后端和direct routing
VxLAN,全称Virtual extensible Local Area Network(虚拟可扩展局域网),是VLAN扩展方案草案,采用的是MAC in UDP封装方式,是NVo3(Network Virtualization over Layer3)中的一种网络虚拟化技术,如图11-8所示。具体实现方式为:将虚拟网络的数据帧添加到VxLAN首部后,封装在物理网络的UDP报文中,然后以传统网络的通信方式传送该UDP报文,待其到达目的主机后,去掉物理网络报文的头部信息以及VxLAN首部,然后将报文交付给目的终端,如图11-9所示的拓扑结构中,跨节点的Pod间通信即为如此。不过,整个过程中通信双方对物理网络无所感知。
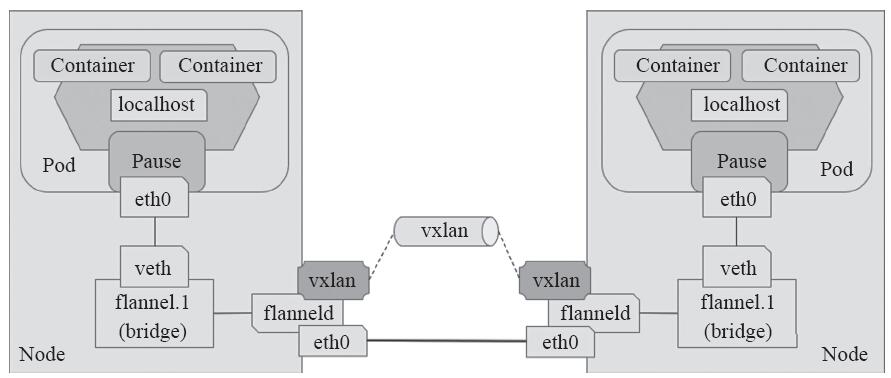
图11-8 flannel VxLAN后端

图11-9 flannel VxLAN Direct Routing后端
VxLAN技术的引入使得逻辑网络拓扑和物理网络拓扑实现了一定程度的解耦,网络拓扑的配置对于物理设备的配置的依赖程度有所降低,配置更灵活更方便。另外,VLAN技术解决了二层网络广播域分割的问题,提供了多租户的良好支持,通过VxLAN进行分割,各个租户可以独立组网、通信。但是,为了确保VxLAN机制通信过程的正确性,涉及VxLAN通信的IP报文一律不能分片,这就要求在物理网络的链路层实现中必须提供足够大的MTU值,或者修改其MTU值以保证VxLAN报文的顺利传输。不过,降低默认MTU值,以及额外的首部开销,必然会影响到其报文传输性能。
对于Kubernetes 1.7及以后的版本来说,flannel项目官方给出的在线配置方式清单中的默认配置即为VxLAN后端,它定义在kube-system名称空间ConfigMap资源kube-flannel-cfg中,它以10.244.0.0/16为Pod网络地址,其配置内容如下所示:
net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "VxLAN" } }
另外,它将通过名为kube-flannel-ds的DaemonSet控制器资源,在每个节点运行一个flannel相关的Pod对象。DaemonSet控制器的Pod模板中使用“hostNetwork:true”配置每个节点上的Pod资源直接共享使用节点的网络名称空间以完成网络配置,其配置结果直接生效于节点的根网络名称空间。
传统的VxLAN后端使用隧道网络转发叠加网络的通信报文会导致不少的流量开销,于是flannel的VxLAN后端还支持DirectRouting模式,它通过添加必要的路由信息使用节点的二层网络直接发送Pod的通信报文,仅在跨IP网络时,才启用传统的隧道方式转发通信流量。由于大部分场景中都省去了隧道首部开销,因此DirectRouting通信模式的性能基本接近于直接使用二层物理网络,其架构模型如图11-9所示。
将flannel项目官方提供的配置清单下载至本地,如存储为Master节点上的/etc/kubernetes/manifests/kube-flannel.yaml文件,而后将其ConfigMap资源kube-flannel-cfg的data字段中的网络配置部分修改为如下内容所示,并使用“kubectl apply”命令重新应用于集群中即可:
net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "VxLAN", "Directrouting": true } }
配置完成后,在每个节点上执行路由查看命令“ip route show”可以看到其生成的路由规则,如下所示的结果是在本书的部署示例拓扑环境中的node01上生成的路由信息,其中,10.244.1.0/24网络位于本机上(node01节点),其他的目标网络则分别位于集群中的每个主机之上,包括master节点:
10.244.0.0/24 via 172.16.0.70 dev ens33 10.244.1.0/24 dev cni0 proto kernel scope link src 10.244.1.1 10.244.2.0/24 via 172.16.0.67 dev ens33 10.244.3.0/24 via 172.16.0.68 dev ens33
此时,在各个集群节点上执行“iptables-nL”命令可以看到,iptables filter表的FORWARD链上由其生成了如下两条转发规则,它显式放行了10.244.0.0/16网络进出的所有报文,用于确保由物理接口接收或发送的目标地址或源地址为10.244.0.0/16网络的所有报文均能够正常通行。这些是Direct Routing模式得以实现的必要条件:
target prot opt source destination ACCEPT all -- 10.244.0.0/16 0.0.0.0/0 ACCEPT all -- 0.0.0.0/0 10.244.0.0/16
各个节点上依然存在flannel相关接口,原因是对于那些无法通过直接路由到达的主机上的Pod(非同一个二层网络),它依然是采用VxLAN的隧道转发机制。按需启动两个Pod测试其通信,并通过相关接口捕获通信报文即可分析其结果。
注意 为了保证所有Pod均能得到正确的网络配置,建议在创建Pod资源之前事先配置好网络插件,甚至是事先了解并根据自身业务需求测试完成中意的目标网络插件,在选型完成后再部署Kubernetes集群,而尽量避免中途修改,否则有些Pod资源可能会需要重建。
VxLAN Directrouting后端转发模式同时兼具了VxLAN后端和host-gw后端的优势,既保证了传输性能,又具备了跨二层网络转发报文的能力。
另外,VxLAN后端的可用配置参数除了Type之外还有如下几个,它们都有其默认值,在用户需要自定义参数时可显式给出相关的配置。
·Type:VxLAN,字符串。
·VNI:VxLAN的标识符,默认为1;数值型数据。
·Port:用于发送封装的报文的UDP端口,默认为8472;数值型数据。
·GBP:全称为Group Based Policy,配置是否启用VxLAN的基于组的策略机制,默认为否;布尔型数据。
·DirectRouting:是否为同一个二层网络中的节点启用直接路由机制,类似于host-gw后端的功能;此种场景下,VxLAN仅用于为那些不在同一个二层网络中的节点封装并转发报文;布尔型数据。
1.2.3 host-gw后端
host-gw后端通过添加必要的路由信息使用节点的二层网络直接发送Pod的通信报文,其工作方式类似于VxLAN后端中direct routing的功能,但不包括其VxLAN的隧道转发能力。其工作模型示意图如图11-10所示。
编辑kube-flannel配置清单,将ConfigMap资源kube-flannel-cfg的data字段中网络配置部分修改为如下所示的内容,并使用“kubectl apply”命令重新应用于集群中即可配置flannel使用host-gw后端:
net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "host-gw" } }
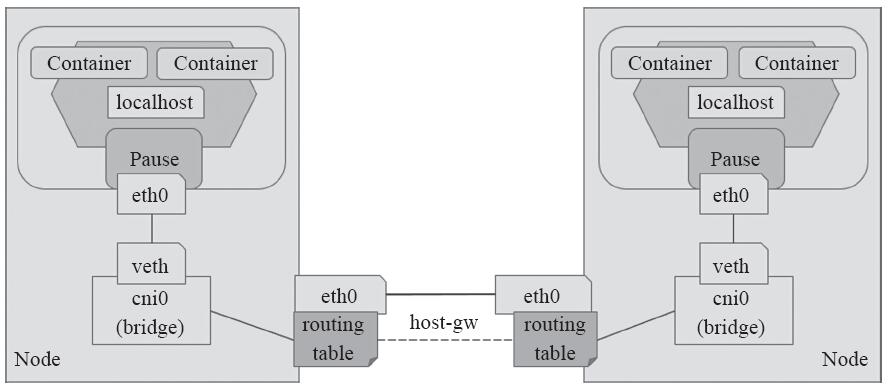
图11-10 host-gw后端
配置完成后,各节点会生成类似于VxLAN direct routing一样的路由及iptables规则以实现二层转发Pod网络的通信报文,省去了隧道转发模式的额外开销。不过,对于非同一个二层网络的报文的转发,host-gw则无能为力。
类似host-gw或VxLAN direct routing这种使用静态路由的方式来实现二层转发虽然较之VxLAN有着更低的资源开销和更好的性能表现,但在Kubernetes集群规模较大时其路由信息的规模也将变得庞大且不易维护。
此外,flannel自身并不具备为Pod网络实施网络策略以实现其网络通信隔离的能力,但它能够借助于Canal项目构建网络策略功能。
1.3 网络策略
网络策略(Network Policy)是用于控制分组的Pod资源彼此之间如何进行通信,以及分组的Pod资源如何与其他网络端点进行通信的规范。它用于为Kubernetes实现更为精细的流量控制,实现租户隔离机制。Kubernetes使用标准的资源对象“NetworkPolicy”供管理员按需定义网络访问控制策略。
1.3.1 网络策略概述
Kubernetes的网络策略功能由其所使用的网络插件实现,因此,仅在使用那些支持网络策略功能的网络插件时才能够配置网络策略,如Calico、Canal及kube-router等。每种解决方案各有其特定的网络策略实现方式,它们的实现或依赖于节点自身的功能,或借助于Hypervisor的特性,也可能是网络自身的功能。Calico的calico/kube-controllers即为Calico项目中用于将用户定义的网络策略予以实现的组件,它主要依赖于节点的iptables来实现访问控制功能,如图11-11所示。其他支持网络策略的插件也有类似的将网络策略加以实现的“策略控制器”或“策略引擎”。

图11-11 网络策略组件构架
策略控制器用于监控创建Pod时所生成的新API端点,并按需为其附加网络策略。当发生需要配置策略的事件时,侦听器会监视到变化,控制器随即响应以进行接口配置和策略应用。
Pod的网络流量包含“流入”(Ingress)和“流出”(Egress)两种方向,每种方向的控制策略则包含“允许”和“禁止”两种。默认情况下,Pod处于非隔离状态,它们的流量可以自由来去。一旦有策略通过选择器规则将策略应用于Pod,那么所有未经明确允许的流量都将被网络策略拒绝,不过,其他未被选择器匹配到的Pod不受影响。
注意 Kubernetes自1.8版本起才支持Egress网络策略,此前的版本仅支持Ingress网络策略。
1.3.2 部署Canal提供网络策略功能
Canal代表了针对云原生应用程序的最佳策略网络解决方案,旨在让用户轻松地将Calico和flannel网络部署在一起作为统一的网络解决方案,将Calico的网络策略执行与Calico和flannel叠加以及非叠加网络连接选项的丰富功能相结合,如图11-12所示。
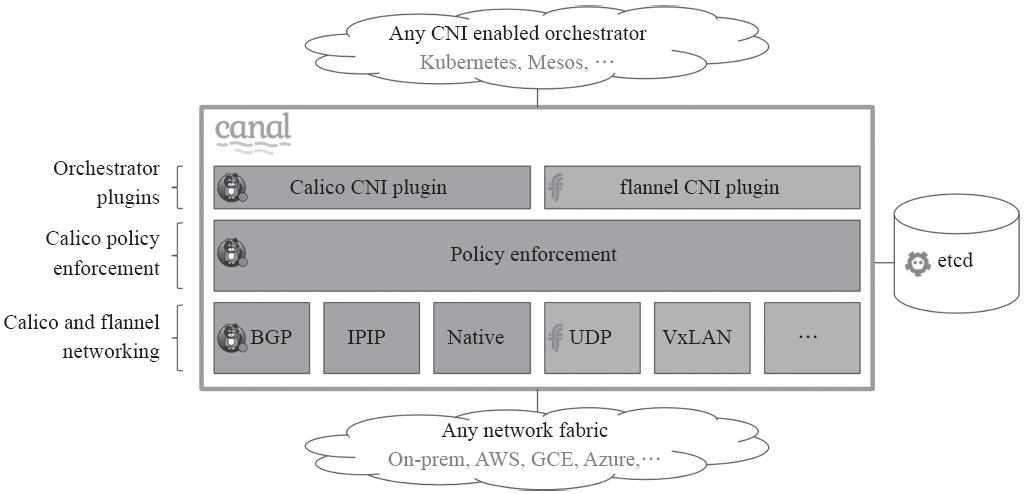
图11-12 Canal项目架构组件
换句话说,Calico项目既能够独立地为Kubernetes集群提供网络解决方案和网络策略,也能与flannel结合在一起,由flannel提供网络解决方案,而Calico此时仅用于提供网络策略,这时我们也可以将Calico称为Canal。Calico将数据存储于etcd中,它支持选择使用专用的etcd存储,也能够以Kubernetes API Server作为后端存储,这里选择以第二种方式进行。
注意 结合flannel工作时,Calico提供的默认配置清单中是以flannel默认使用的10.244.0.0/16为Pod网络,因此,请确保kube-controller-manager程序在启动时通过--cluster-cidr选项设置使用了此网络地址,并且--allocate-node-cidrs的值应设置为true。
部署之前,要在启用了RBAC的Kubernetes集群中设置必要的相关资源:
~]$ kubectl apply -f https://docs.projectcalico.org/v3.2/getting-started/kubernetes/ installation/hosted/canal/rbac.yaml
接下来即可部署Canal提供网络策略:
~]$ kubectl apply -f https://docs.projectcalico.org/v3.2/getting-started/kubernetes/ installation/hosted/canal/canal.yaml
需要注意的是,Canal目前直接使用Calico和flannel项目,代码本身并没有任何修改。因此,目前的Canal只是一种部署模式,用于安装和配置项目,从用户和编排系统的角度无缝地作为单一网络解决方案协同工作。未来,Canal项目可能会对Calico和flannel项目进行代码更改,实现安装和配置的进一步简化。
1.3.3 配置网络策略
Kubernetes系统中,报文流入和流出的核心组件是Pod资源,因此它们也是网络策略功能生效的主要目标,因此,NetworkPolicy对象也要使用标签选择器事先选择出一组Pod资源作为控制对象。一般来说,NetworkPolicy是定义在一组Pod资源上的用于管控入站流量的“Ingress规则”,或者说是管理出站流量的“Egress规则”,也可以是二者组合定义,而仅部分生效还是全部生效则需要由spec.policyTypes予以定义,如图11-13所示。
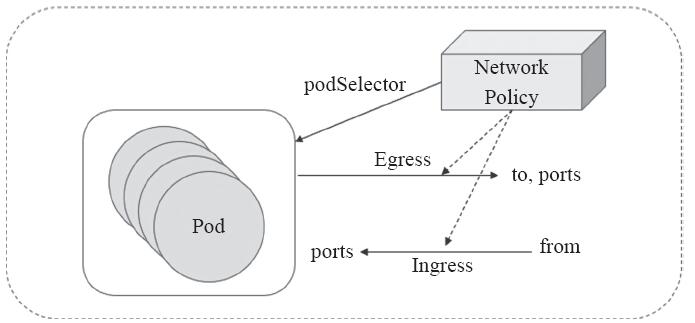
图11-13 网络策略示意图
默认情况下,Pod对象既可以接受来自任何来源的流量,也能够向外部发出期望的所有流量。而附加网络策略机制后,Pod对象会因NetworkPolicy对象的选定而被隔离:一旦名称空间中有任何NetworkPolicy对象匹配了某特定的Pod对象,则该Pod将拒绝Network-Policy所不允许的一切连接请求,而那些未被任何NetworkPolicy对象匹配到的其他Pod对象仍可接受所有流量。因此,就特定的Pod集合来说,入站和出站流量默认均处于放行状态,除非有规则能够明确匹配到它。然而,一旦在spec.policyTypes中指定了生效的规则类型,却在networkpolicy.spec字段中嵌套定义了没有任何规则的Ingress或Egress字段时,则表示拒绝相关方向上的一切流量。
定义网络策略时常用到的术语及说明具体如下。
·Pod组:由网络策略通过Pod选择器选定的一组Pod的集合,它们是规则生效的目标Pod;可由NetworkPolicy对象通过macthLabel或matchExpression选定。
·Egress:出站流量,即由特定的Pod组发往其他网络端点的流量,通常由流量的目标网络端点(to)和端口(ports)来进行定义。
·Ingress:入站流量,即由其他网络端点发往特定Pod组的流量,通常由流量发出的源站点(from)和流量的目标端口所定义。
·端口(ports):TCP或UDP的端口号。
·端点(to,from):流量目标和流量源相关的组件,它可以是CIDR格式的IP地址块(ipBlock)、网络名称空间选择器(namespaceSelector)匹配的名称空间,或Pod选择器(podSelector)匹配的Pod组。
无论是Ingress还是Egress流量,与选定的某Pod组通信的另一方都可使用“网络端点”予以描述,它通常是某名称空间中的一个或一组Pod资源,由namespaceSelector选定名称空间后,经由ipBlock或podSelector进行指定。Pod集合的选定方式如图11-14所示。
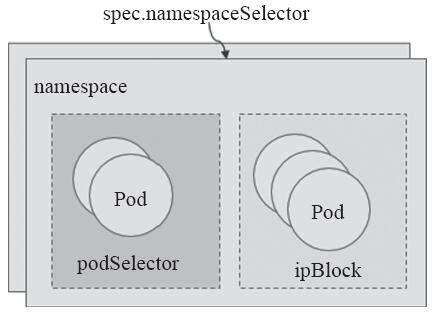
图11-14 Pod集合的选定方式
在Ingress规则中,网络端点也称为“源端点”,它们用from字段进行标识,而在Egress规则中,网络端点也称为“目标端点”,它们用to字段进行标识,如图11-13所示。不过,在未定义Ingress或Egress规则时,相关方向的流量均为“允许”,即默认为非隔离状态。而一旦在networkpolicy.spec中明确给出了Ingress或Egress字段,则它们的from或to字段的值就成了白名单列表,而空值意味着所有端点,即不限制访问。
1.3.4 管控入站流量
以提供服务为主要目的的Pod对象通常是请求流量的目标对象,但它们的服务未必应该为所有网络端点所访问,这就有必要对它们的访问许可施加控制。networkpolicy.spec中嵌套的Ingress字段用于定义入站流量规则,就特定的Pod集合来说,入站流量默认处于放行状态,除非在所有入站策略中,至少有一条规则能够明确匹配到它。Ingress字段的值是一个对象列表,它主要由以下两个字段组成。
·from<[]Object>:可访问当前策略匹配到的Pod对象的源地址对象列表,多个项目之间的逻辑关系为“逻辑或”的关系;若未设置此字段或其值为空,则匹配一切源地址(默认的访问策略为不限制);如果此字段至少有一个值,那么它将成为放行的源地址白名单,仅来源于此地址列表中的流量允许通过。
·ports<[]Object>:当前策略匹配到的Pod集合的可被访问的端口对象列表,多个项目之间的逻辑关系为“逻辑或”的关系;若未设置此字段或其值为空,则匹配Pod集合上的所有端口(默认的访问策略为不限制);如果此字段至少有一个值,那么它将成为允许被访问的Pod端口白名单列表,仅入站流量的目标端口处于此列表中方才准许通过。
需要注意的是,NetworkPolicy资源属于名称空间级别,它的有效作用范围为其所属的名称空间。
1.设置默认的Ingress策略
必要时,用户可以创建一个NetworkPolicy来为名称空间设置一个“默认”的隔离策略,该策略选择所有的Pod对象,而后允许或拒绝任何到达这些Pod的入站流量。例如下面的策略示例,其通过policyTypes字段指明要生效Ingress类型的规则,但未定义任何Ingress字段,因此不能匹配到任一源端点,从而拒绝所有入站流量:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: deny-all-ingress spec: podSelector: {} policyTypes: ["Ingress"]
若要将默认策略设置为允许所有的入站流量,则只需要显式定义Ingress字段,并将其值设置为空以匹配所有源端点即可,如下面示例中的定义。不过,没有为入站流量定义任何规则时,本身的默认规则即为允许访问,因此允许所有相关的入站流量时,本身无须定义默认规则,下面的示例只是为说明规则的定义格式:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-all-ingress spec: podSelector: {} policyTypes: ["Ingress"] ingress: - {}
实践中,通常将默认策略设置为拒绝所有的入站流量,而后显式放行允许的源端点的入站流量。
2.放行特定的入站流量
在Ingress规则中嵌套from和ports字段即可匹配特定的入站流量,仅定义from字段时将隐含本地Pod资源组的所有端口,而仅定义ports字段时则表示隐含所有的源端点。from和ports同时定义时表示隐含“逻辑与”关系,它将匹配那些同时满足from和ports的定义的入站流量,即那些来自from指定的源端点,访问由当前NetworkPolicy的podSelector匹配的当前名称空间的Pod资源组上所指定的ports的请求,如图11-15所示。
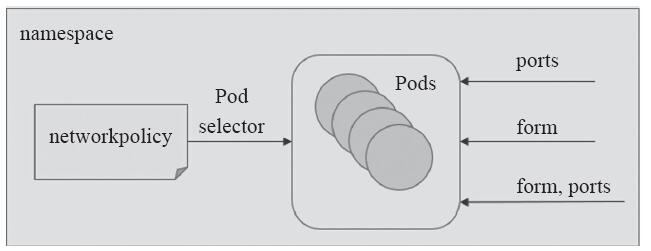
图11-15 Ingress规则的组成方式
from字段的值是一个对象列表,它可嵌套使用ipBlock、namespaceSelector和podSelector字段来定义流量来源,此三个字段匹配Pod资源的方式各有不同,同时使用两个或以上的字段,彼此之间隐含“逻辑或”关系。
·ipBlock"Object" :根据IP地址或网络地址块选择流量源端点。
·namespaceSelector"Object" :基于集群级别的标签挑选名称空间,它将匹配由此标签选择器选出的所有名称空间内的所有Pod对象;赋予字段以空值来表示挑选所有的名称空间,即源站点为所有名称空间内的所有Pod对象。
·podSelector"Object" :于NetworkPolicy所在的当前名称空间内基于标签选择器挑选Pod资源,赋予字段以空值来表示挑选当前名称空间内的所有Pod对象。
·ports字段的值也是一个对象列表,它嵌套port和protocol来定义流量的目标端口,即由NetworkPolicy匹配到的当前名称空间内的所有Pod资源上的端口。
·port
·protocol
下面配置清单中的网络策略示例定义了如何开放myapp pod资源给相应的源站点访问:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-myapp-ingress namespace: default spec: podSelector: matchLabels: app: myapp policyTypes: ["Ingress"] ingress: - from: - ipBlock: cidr: 10.244.0.0/16 except: - 10.244.3.0/24 - podSelector: matchLabels: app: myapp ports: - protocol: TCP port: 80
它将default名称空间中拥有标签“app=myapp”的Pod资源的80/TCP端口开放给10.244.0.0/16网络内除10.244.3.0/24子网中的所有源端点,以及当前名称空间中拥有标签“app=myapp”的所有Pod资源访问,其他未匹配到的源端点的流量则取决于其他网络策略的定义,若没有任何匹配策略,则默认为允许访问。
1.3.5 管控出站流量
除非是仅于当前名称空间中即能完成所有的目标功能,否则,大多数情况下,一个名称空间中的Pod资源总是有对外请求的需求,如向CoreDNS请求解析名称等。因此,通常应该将出站流量的默认策略设置为准许通过。但如果有必要对其实施精细管理,仅放行那些有对外请求需要的Pod对象的出站流量,则也可先为名称空间设置“禁止所有”默认策略,而后定义明确的“准许”策略。
networkpolicy.spec中嵌套的Egress字段用于定义入站流量规则,就特定的Pod集合来说,出站流量一样默认处于放行状态,除非在所有入站策略中至少有一条规则能够明确匹配到它。Egress字段的值是一个字段列表,它主要由以下两个字段组成。
·to<[]Object> :由当前策略匹配到的Pod资源发起的出站流量的目标地址列表,多个项目之间为“或”(OR)关系;若未定义或字段值为空则意味着应用于所有目标地址(默认为不限制);若明确给出了主机地址列表,则只有目标地址匹配列表中的主机地址的出站流量被放行。
·ports<[]Object> :出站流量的目标端口列表,多个端口之间为“或”(OR)关系;若未定义或字段值为空则意味着应用于所有端口(默认为不限制);若明确给出了端口列表,则只有目标端口匹配列表中的端口的出站流量被放行。
Egress规则中,to和ports字段的值都是对象列表格式,它们可内嵌的字段分别与Ingress规则中的from和ports相同,区别仅是作用到的流量方向相反,如图11-16所示。

图11-16 Egress字段的组成方式
1.设置默认Egress策略
类似于使用Ingress的使用方式,用户也可以通过创建一个NetworkPolicy对象来为名称空间设置一个默认的隔离策略,该策略选择所有的Pod对象,而后允许或拒绝由这些Pod发出的所有出站流量。例如下面的策略示例,它通过policyTypes字段指明要生效Egress类型的规则,但未定义任何Egress字段,因此不能匹配到任何目标端点,从而拒绝所有的入站流量:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: deny-all-egress spec: podSelector: {} policyTypes: ["Egress"]
实践中,需要进行严格隔离的环境通常将默认策略设置为拒绝所有出站流量,而后显式放行允许到达的目标端点的出站流量。
2.放行特定的出站流量
下面的配置清单示例中定义了一个Egress规则,它对来自拥有“app=tomcat”的Pod对象的,到达标签为“app=nginx”的Pod对象的80端口,以及到达标签为“app=mysql”的Pod对象的3306端口的流量给予放行:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-tomcat-egress namespace: default spec: podSelector: matchLabels: app: tomcat policyTypes: ["Egress"] egress: - to: - podSelector: matchLabels: app: nginx ports: - protocol: TCP port: 80 - to: - podSelector: matchLabels: app: mysql ports: - protocol: TCP port: 3306
需要注意的是,此配置清单中仅定义了出站规则,将入站流量的默认规则设置为拒绝所有时,还应该为具有标签“app=tomcat”的Pod对象放行入站流量。
1.3.6 隔离名称空间
实践中,通常需要彼此隔离所有的名称空间,但应该允许它们都能够与kube-system名称空间中的Pod资源进行流量交换,以实现监控和名称解析等各种管理功能。下面的配置清单示例为default名称空间定义了相关的规则,在出站和入站流量默认均为拒绝的情况下,它用于放行名称空间内部的各Pod对象之间的通信,以及与kube-system名称空间内各Pod间的通信:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: namespace-deny-all namespace: default spec: policyTypes: ["Ingress","Egress"] podSelector: {} --- apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: namespace- namespace: default spec: policyTypes: ["Ingress","Egress"] podSelector: {} ingress: - from: - namespaceSelector: matchExpressions: - key: name operator: In values: ["default","kube-system"] egress: - to: - namespaceSelector: matchExpressions: - key: name operator: In values: ["default","kube-system"]
需要注意的是,有些管理员可能会把一些系统附件部署到专有的名称空间中,例如把Prometheus监控系统部署到prom名称空间中等,所有这类的具有管理功能的附件所在的名称空间与每一个特定名称空间的出入流量都应该被放行。
1.3.7 网络策略应用案例
假设有名为testing的名称空间内运行着一组nginx Pod和一组myapp Pod。要求实现如下目标。
1)myapp Pod仅允许来自nginx Pod的流量访问其80/TCP端口,但可以向nginx Pod的所有端口发出出站流量。
2)nginx Pod允许任何源端点对其80/TCP端口的访问,并能够向任意端点发出出站流量。
3)myapp Pod和nginx Pod都可与kube-system名称空间的任意Pod进行任何类型的通信,以便于可以使用由kube-dns提供的名称解析服务等。
如图11-17所示,出站和入站的默认策略均为“禁止”。
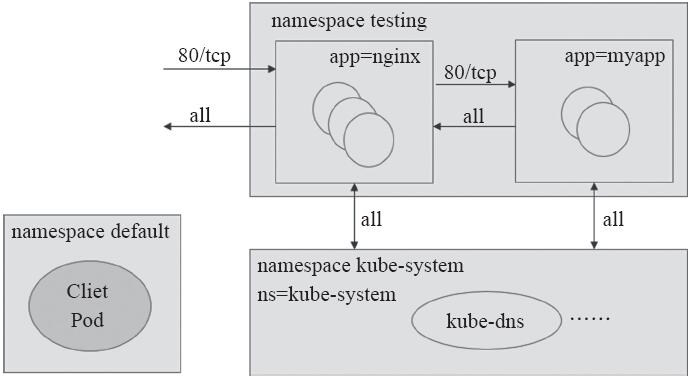
图11-17 案例拓扑
下面是测试实现步骤。
第一步: 创建testing名称空间,并于其内基于Deployment控制器创建用于测试用的nginx Pod和myapp Pod各一个,创建相关Pod资源时顺便为其创建与Deployment控制器同名的Service资源:
~]$ kubectl create namespace testing ~]$ kubectl run nginx --image=nginx:alpine --replicas=1 --namespace=testing \ --port 80 --expose --labels app=nginx ~]$ kubectl run myapp --image=ikubernetes/myapp:v1 --replicas=1 \ --namespace=testing --port 80 --expose --labels app=myapp
另外,为了便于在网络策略规则中引用kube-system名称空间,这里为其添加标签“ns=kube-system”:
~]$ kubectl label namespace kube-system ns=kube-system
待相关资源创建完成后,即可通过与其相关的Service资源的名称访问相关的服务。例如,另外启动一个终端,使用kubectl命令在default名称空间中创建一个用于测试的临时交互式客户端:
~]$ kubectl run cirros-$RANDOM --namespace=default --rm -it --image=cirros -- sh / #
而后基于此客户端分别测试访问nginx和myapp的服务,名称空间的默认网络策略为准许访问,接下来确认其访问请求可正常通过:
/ # curl nginx.testing …… <title>Welcome to nginx!</title> …… / # curl myapp.testing Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a> / #
第二步: 定义网络策略清单文件(testing-netpol-denyall.yaml),将testing名称空间的入站及出站的默认策略修改为拒绝访问,并再一次进行访问测试:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: deny-all-traffic namespace: testing spec: podSelector: {} policyTypes: - Ingress - Egress
接下来,将testing-netpol-denyall.yaml定义的默认策略deny-all-traffic予以应用,为testing名称空间设置默认的网络策略:
$ kubectl apply -f testing-netpol-denyall.yaml
回到第一步创建的交互式客户端,再次对nginx和myapp发起访问测试。为了避免长时间等待,这里为curl命令添加--connect-timeout选项为其定义连接超时时长。由下面的命令可知,此时无法再访问到nginx和myapp的相关服务:
/ # curl --connect-timeout 2 nginx.testing curl: (28) connect() timed out! / # curl --connect-timeout 2 myapp.testing curl: (28) connect() timed out! / #
第三步: 定义流量放行规则配置清单nginx-allow-all.yaml,放行nginx Pod之上80/TCP端口的所有流量:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: nginx-allow-all namespace: testing spec: podSelector: matchLabels: app: nginx ingress: - ports: - port: 80 - from: - namespaceSelector: matchLabels: ns: kube-system egress: - to: policyTypes: - Ingress - Egress
将上述清单文件中定义的网络策略应用至集群中以创建相应的网络策略:
~]$ kubectl apply -f nginx-allow-all.yaml
而后再次回到交互式测试客户端发起访问请求进行测试,由下面的命令结果可知,nginx已经能够正常访问,这同时也意味着由kube-system名称空间中的kube-dns进行的名称解析服务也为可用状态:
/ # curl --connect-timeout 2 nginx.testing …… <title>Welcome to nginx!</title> …… / #
第四步: 定义网络策略配置清单myapp-allow.yaml,放行testing名称空间中来自nginx Pod的发往myapp Pod的80/TCP的访问流量,以及myapp Pod发往nginx Pod的所有流量。另外,允许myapp Pod与kube-system名称空间的任何Pod进行交互的所有流量:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: myapp-allow namespace: testing spec: podSelector: matchLabels: app: myapp ingress: - from: - podSelector: matchLabels: app: nginx ports: - port: 80 - from: - namespaceSelector: matchLabels: ns: kube-system egress: - to: - podSelector: matchLabels: app: nginx - to: - namespaceSelector: matchLabels: ns: kube-system policyTypes: - Ingress - Egress
接下来首先创建清单中定义的网络策略:
~]$ kubectl apply -f myapp-allow.yaml networkpolicy.networking.k8s.io "myapp-allow" configured
而后切换至此前在专用终端中创建的临时使用的交互式Pod,对myapp Pod发起访问请求。由下面的命令结果可知,其访问被拒绝:
# curl --connect-timeout 2 http://myapp.testing curl: (28) connect() timed out! / #
myapp Pod仅允许来自nginx Pod对其80/TCP端口的访问,于是,这里进入testing名称空间中的是nginx Pod的交互式接口,使用wget命令对myapp Pod发起访问请求,如下面的命令所示:
~]$ kubectl exec -it nginx-b477df957-jb2nf -n testing -- /bin/sh / # wget http://myapp.testing -O - -q Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a> / #
需要注意的是,这里的nginx Pod经由Deployment控制器创建,其名称格式为两级Hash字符串,读者在执行测试操作时要转换为实际创建的标识符。如果所有测试均能通过,则表示网络策略都已经正常生效。此示例中涉及的访问控制基本上能够类比到大多数场景中策略设置的需求,这里还请读者细细揣摩其设置逻辑。
1.4 Calico网络插件
Calico是一个开源虚拟化网络方案,用于为云原生应用实现互联及策略控制。与Flannel相比,Calico的一个显著优势是对网络策略(network policy)的支持,它允许用户动态定义ACL规则控制进出容器的数据报文,实现为Pod间的通信按需施加安全策略。事实上,Calico可以整合进大多数主流的编排系统,如Kubernetes、Apache Mesos、Docker和OpenStack等。
Calico本身是一个三层的虚拟网络方案,它将每个节点都当作路由器(router),将每个节点的容器都当作是“节点路由器”的一个终端并为其分配一个IP地址,各节点路由器通过BGP(Border Gateway Protocol)学习生成路由规则,从而将不同节点上的容器连接起来。因此,Calico方案其实是一个纯三层的解决方案,通过每个节点协议栈的三层(网络层)确保容器之间的连通性,这摆脱了flannel host-gw类型的所有节点必须位于同一二层网络的限制,从而极大地扩展了网络规模和网络边界。如图11-18所示的是Calico系统示意图。
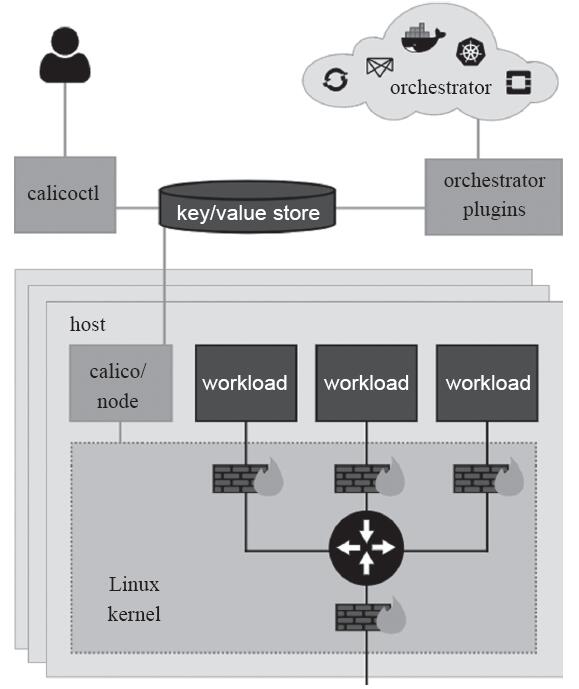
图11-18 Calico系统示意图
BGP是互联网上一个核心的去中心化自治路由协议,它通过维护IP路由表或“前缀”表来实现自治系统(AS)之间的可达性,属于矢量路由协议。不过,考虑到并非所有的网络都能支持BGP,以及Calico控制平面的设计要求物理网络必须是二层网络,以确保vRouter间均直接可达,路由不能够将物理设备当作下一跳等原因,为了支持三层网络,Calico还推出了IP-in-IP叠加的模型,它也使用Overlay的方式来传输数据。IPIP的包头非常小,而且也是内置在内核中,因此理论上它的速度要比VxLAN快一点,但安全性更差。Calico 3.x的默认配置使用的是IPIP类型的传输方案而非BGP。
1.4.1 Calico工作特性
Calico利用Linux内核在每一个计算节点上实现了一个高效的vRouter(虚拟路由器)进行报文转发,而每个vRouter都通过BGP负责把自身所属的节点上运行的Pod资源的IP地址信息基于节点的agent程序(Felix)直接由vRouter生成路由规则向整个Calico网络内进行传播,不过,尽管小规模部署可以直接互联,但大规模网络还是建议使用BGP路由反射器(route reflector)来完成。Felix也支持在每个节点上按需生成ACL(Access Control List)从而实现安全策略,如隔离不同的租户或项目的网络通信。vRouter利用BGP通告本节点上现有的地址分配信息,每个vRouter均接入BGP路由反射器以实现控制平面扩展。
Calico承载的各Pod资源直接通过vRouter经由基础网络进行互联,它非叠加、无隧道、不使用VRF表,也不依赖于NAT,因此每个工作负载都可以直接配置使用公网IP接入互联网,当然,也可以按需使用网络策略控制它的网络连通性。
(1)经IP路由直连
Calico中,Pod收发的IP报文由所在节点的Linux内核路由表负责转发,并通过iptables规则实现其安全功能。某Pod对象发送报文时,Calico应确保节点总是作为下一跳MAC地址返回,不管工作负载本身可能配置什么路由,而发往某Pod对象的报文,其最后一个IP跃点就是Pod所在的节点,也就是说,报文的最后一程即由节点送往目标Pod对象,如图11-19所示。

图11-19 经IP路由直连
需为某Pod对象提供连接时,系统上的专用插件(如Kubernetes的CNI)负责将需求通知给Calico Agent。收到消息后,Calico Agent会为每个工作负载添加直接路径信息到工作负载的TAP设备(如veth)。而运行于当前节点的BGP客户端监控到此类消息后会调用路由reflector向工作于其他节点的BGP客户端进行通告。
(2)简单、高效、易扩展
Calico未使用额外的报文封装和解封装,从而简化了网络拓扑,这也是Calico高性能、易扩展的关键因素。毕竟,小的报文减少了报文分片的可能性,而且较少的封装和解封装操作也降低了对CPU的占用。此外,较少的封装也易于实现报文分析,易于进行故障排查。
创建、移动或删除Pod对象时,相关路由信息的通告速度也是影响其扩展性的一个重要因素。Calico出色的扩展性缘于与互联网架构设计原则别无二致的方式,它们都使用了BGP作为控制平面。BGP以高效管理百万级的路由设备而闻名于世,Calico自然可以游刃有余地适配大型IDC网络规模。另外,由于Calico各工作负载使用基IP直接进行互联,因此它还支持多个跨地域的IDC之间进行协同。
(3)较好的安全性
原则上,Calico网络允许IDC中的任何工作负载与其他任意目标进行通信,但管理员或用户却未必期望如此,在多租户IDC中隔离租户网络几乎是必然之需。于是,Calico操纵节点上的iptables规则以管控工作负载的互联许可。此种iptables规则操纵功能是节点间的警戒哨,负责阻挡任何非许可流量,并防止通过工作负载危及节点自身。
·严格的域间流量分隔:运行于某个租户虚拟网络内的应用应严禁访问其他租户的应用,这种流量分隔是由久经考验的Linux内核中的ACL子系统予以实现的。
·精细的策略规则:实现了租户间隔离的网络方案大多并没有额外实现细粒度的安全策略,而Calico通过使用Linux内建的ACL扩展来支持一众安全规则,任何可由ACL支持的功能均能通过Calico实现。
·简洁而不简单:Calico直接使用IP网络,无须任何地址转换或隧道承载的机制实现了一个简洁的“WYSIWYG”(What You See Is What You Get)网络模型,它可以清晰地标识出每个报文从哪儿来,到哪儿去。于是,管理员可因此而清晰地理解流量的来去。
1.4.2 Calico系统架构
概括来说,Calico主要由Felix、Orchestrator Plugin、etcd、BIRD和BGP Router Reflector等组件组成,其组件架构如图11-20所示。
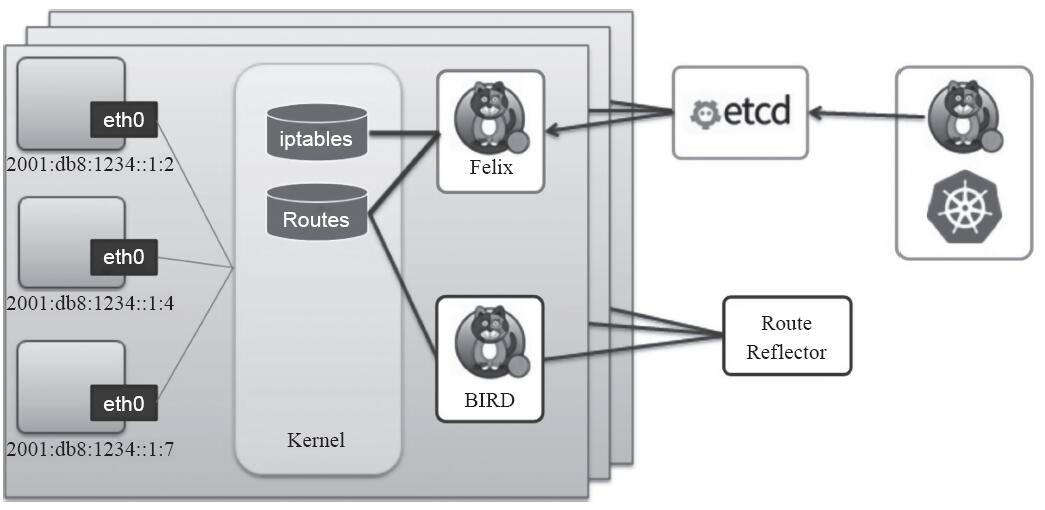
图11-20 Calico系统组件
·Felix:Calico Agent,运行于每个节点。
·Orchestrator Plugin:编排系统(如Kubernetes、OpenStack等)以将Calico整合进系统中的插件,例如Kubernetes的CNI。
·etcd:持久存储Calico数据的存储管理系统。
·BIRD:用于分发路由信息的BGP客户端。
·BGP Route Reflector:BGP路由反射器,可选组件,用于较大规模的网络场景。
1.Felix
Felix运行于各节点的用于支持端点(VM或Container)构建的守护进程,它负责生成路由和ACL,以及其他任何由节点用到的信息,从而为各端点构建连接机制。Felix在各编排系统中主要负责以下任务。
首先是接口管理(Interface Management)功能,负责为接口生成必要的信息并送往内核,以确保内核能够正确处理各端点的流量,尤其是要确保各节点能够响应目标MAC为当前节点上各工作负载的MAC地址的ARP请求,以及为其管理的接口打开转发功能。另外,它还要监控各接口的变动以确保规则能够得到正确的应用。
其次是路由规划(Route Programming)功能,其负责为当前节点运行的各端点在内核FIB(Forwarding Information Base)中生成路由信息,以保证到达当前节点的报文可正确转发给端点。
再次是ACL规划(ACL Programming)功能,负责在Linux内核中生成ACL,用于实现仅放行端点间的合法流量,并确保流量不能绕过Calico的安全措施。
最后是状态报告(State Reporting)功能,负责提供网络健康状态的相关数据,尤其是报告由其管理的节点上的错误和问题。这些报告数据会存储于etcd,供其他组件或网络管理员使用。
2.编排系统插件
编排系统插件(Orchestrator Plugin)依赖于编排系统自身的实现,故此并不存在一个固定的插件以代表此组件。编排系统插件的主要功能是将Calico整合进系统中,并让管理员和用户能够使用Calico的网络功能。它主要负责完成API的转换和反馈输出。
编排系统通常有其自身的网络管理API,网络插件需要负责将对这些API的调用转为Calico的数据模型并存储于Calico的存储系统中。如果有必要,网络插件还要将Calico系统的信息反馈给编排系统,如Felix的存活状态,网络发生错误时设定相应的端点为故障等。
3.etcd存储系统
Calico使用etcd完成组件间的通信,并以之作为一个持久数据存储系统。根据编排系统的不同,etcd所扮演角色的重要性也因之而异,但它贯穿了整个Calico部署全程,并被分为两类主机:核心集群和代理(proxy)。在每个运行着Felix或编排系统插件的主机上都应该运行一个etcd代理以降低etcd集群和集群边缘节点的压力。此模式中,每个运行着插件的节点都会运行着etcd集群的一个成员节点。
etcd是一个分布式、强一致、具有容错功能的存储系统,这一点有助于将Calico网络实现为一个状态确切的系统:要么正常,要么发生故障。另外,分布式存储易于通过扩展应对访问压力的提升,而避免成为系统瓶颈。另外,etcd也是Calico各组件的通信总线,可用于确保让非etcd组件在键空间(keyspace)中监控某些特定的键,以确保它们能够看到所做的任何更改,从而使它们能够及时地响应这些更改。
4.BGP客户端(BIRD)
Calico要求在每个运行着Felix的节点上同时还要运行一个BGP客户端,负责将Felix生成的路由信息载入内核并通告到整个IDC。在Calico语境中,此组件是通用的BIRD,因此任何BGP客户端(如GoBGP等)都可以从内核中提取路由并对其分发对于它们来说都适合的角色。
BGP客户端的核心功能就是路由分发,在Felix插入路由信息至内核FIB中时,BGP客户端会捕获这些信息并将其分发至其他节点,从而确保了流量的高效路由。
5.BGP路由反射器(BIRD)
在大规模的部署场景中,简易版的BGP客户端易于成为性能瓶颈,因为它要求每个BGP客户端都必须连接至其同一网络中的其他所有BGP客户端以传递路由信息,一个有着N个节点的部署环境中,其存在网络连接的数量为N的二次方,随着N值的逐渐增大,其连接复杂度会急剧上升。因而在较大规模的部署场景中,Calico应该选择部署一个BGP路由反射器,它是由BGP客户端连接的中心点,BGP的点到点通信也就因此转化为与中心点的单路通信模型,如图11-18所示。出于冗余之需,生产实践中应该部署多个BGP路由反射器。对于Calico来说,BGP客户端程序除了作为客户端使用之外,还可以配置成路由反射器。
1.4.3 Calico部署要点
安装Calico需要事先有运行中的Kubernetes 1.1及以上版本的集群,如果要用到网络策略,则Kubernetes版本要1.3.0及以上才可以。另外,还需要一个可由Kubernetes集群各节点访问到的etcd集群。虽然可以让Calico和Kubernetes共同使用同一个etcd集群,然则有些场景中推荐为etcd使用专用集群,如需要获得较好的性能时。
与Kubernetes集群进行整合时,Calico需要提供三个组件,具体如下。
·calico/node:Calico于Kubernetes集群中为每个节点上运行的容器提供Felix Agent和BGP客户端。
·cni-plugin:CNI网络插件,用于整合Calico和kubelet,发现Pod资源,并将其添加进Calico网络,因此,每个运行kubelet的主机都需要配置。
·calico/kube-controllers:Calico网络策略控制器。
Calico的安装有两种方式,一是配置其独立运行于Kubernetes集群之外,但calico/kube-controllers依然需要以Pod资源运行于集群之上。另一种是以插件方式配置Calico完全托管运行于Kubernetes集群之上,不过此种方式要求Kubernetes版本至少在1.4.0以上。
另外,Calico以Kubernetes插件方式部署的实现方式有两种,一是标准托管式部署,即Calico使用专用的etcd存储管理数据持久化及组件间的通信。另一个是以Kubernetes API Server为Datastore,调用Kubernetes的API完成所需的操作。自3.0版本起,Calico官方推荐使用第二种方式,而此前的版本中此种功能尚且不够完善,所推荐的则是第一种部署方式。
再者,Calico既可以单独为Kubernetes系统提供网络服务及网络策略,也可以与flannel整合在一起由flannel实现网络服务而Calico仅提供网络策略。事实上,还有一个本身即是将flannel或Calico合二为一的解决方案Canal,不过,这已经是另一个独立的项目。
需要注意的是,Calico分配的地址池与Kubernetes集群的--pod-network-cidr的值应该保持一致,默认情况下,Calico的配置清单中使用192.168.0.0/16作为Pod网络。不过,如果用户计划将Calico和flannel协同进行部署,则可以在此前已有flannel插件的基础上直接添加Calico。1.4.4节将在讲解独立部署Calico的同时提供网络服务及网络策略,协同flannel的部署方式请读者参考官方文件中的相关介绍进行操作。
1.4.4 部署Calico提供网络服务和网络策略
为了便于简化部署环境及操作复杂度,本节的操作建立在一个刚由kubeadm部署完成的新的Kubernetes集群之上,部署时为--pod-network-cidr选项指定了使用192.168.0.0/16网络以适配Calico的默认网络配置,它还没有添加过任何网络插件。Calico的部署方式极其灵活,这里难以尽述其所有的实现方式,仅以典型应用场景对其加以说明。
Calico 3目前仅支持Kubernetes 1.8及其之后的版本,并且它要求使用一个能够被各组件访问到的键值存储系统,在Kubernetes环境中,可用的选择有etcd v3或Kubernetes API数据存储。本部署示例会将Kubernetes API作为Calico的数据存储取代etcd,这也是在本篇写作时时下最新的稳定版本Calico 3版本中推荐的配置。另外,Calico 3目前对kube-proxy ipvs模式的支持尚且处于试用级别,因此不建议读者在生产环境中使用。
注意 不同版本的Calico的部署方式可能不尽相同,读者需要根据操作时的具体情况参考官方文档来确定具体的部署方案及部署步骤。
在启用了RBAC的Kubernetes集群部署Calico时,需要先创建必要的ClusterRole和ClusterRoleBinding资源。Calico官方给出了标准定义的配置清单,部署时,直接应用在线清单即可,如下面的命令所示:
~]$ kubectl apply –f https://docs.projectcalico.org/v3.2/getting-started/kubernetes/ installation/hosted/rbac-kdd.yaml
应用完成后,它会创建名为calico-node的clusterrole和clusterrolebinding,为相关的Pod资源calico-node的ServiceAccount授予必要的资源管理权限。Kubernetes集群规模小于50节点时,可以类似如下命令部署Calico的各相关组件,它们会创建多个标准的Kubernetes资源及数个自定义的资源:
~]$ kubectl apply -f https://docs.projectcalico.org/v3.2/getting-started/kubernetes/ installation/hosted/kubernetes-datastore/calico-networking/1.7/calico.yaml
可通过如下命令查看calico-node相关的Pod资源于各节点中的部署状态。待所有Pod资源均处于“Running”状态后,即可正常使用其相关的功能:
~]$ kubectl get pods -l k8s-app=calico-node -o wide -n kube-system
工作于IPIP模式的Calico会在每个节点上创建一个tunl0接口(TUN类型虚拟设备)用于封装三层隧道报文。节点上创建的每一个Pod资源,都会由Calico自动创建一对虚拟以太网接口(TAP类型的虚拟设备),其中一个附加于Pod的网络名称空间,另一个(名称以cali为前缀后跟随机字串)留置在节点的根网络名称空间,并经由tunl0封装或解封三层隧道报文。Calico IPIP模式如图11-21所示。
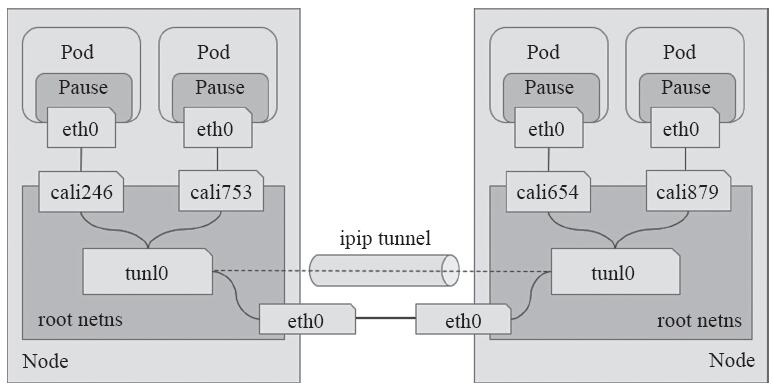
图11-21 Calico IPIP
部署完成后,Calico会在每个节点上生成到达Kubernetes集群中每个节点上的Pod子网的路由信息,下面所示的路由信息是部署示例中node01主机上生成的路由条目,它们由各节点上的BIRD以点对点的方式向网络中的其他节点进行通告并学习其他节点的通告而得:
192.168.0.0/24 via 172.16.0.70 dev tunl0 proto bird onlink blackhole 192.168.1.0/24 proto bird 192.168.2.0/24 via 172.16.0.67 dev tunl0 proto bird onlink 192.168.3.0/24 via 172.16.0.68 dev tunl0 proto bird onlink
在每个节点上创建Pod资源时,由Calico CNI插件为其生成TAP设备并分配地址后,也会在节点的网络名称空间中生成一个新的路由条目,类似如下所示,它指明了发往本节点上某特定Pod IP的报文应该经由的TAP接口:
192.168.1.3 dev cali8bb05ff8b64 scope link
在集群中部署一些Pod资源即可完成集群网络连接测试。假设此时在node01上存在一个IP地址为192.168.1.3的Pod A,以及在node02上存在一个IP地址为192.168.2.4的Pod B,通过Pod A的交互式接口对Pod B发起ping请求,在node01的物理接口上以root用户的身份抓取通信报文,命令及截取的一次通信的往返结果示例如下:
~]# tcpdump -i ens33 -nn ip host 172.16.0.66 and host 172.16.0.67 10:58:03.553589 IP 172.16.0.66 > 172.16.0.67: IP 192.168.1.3 > 192.168.2.4: ICMP echo request, id 4096, seq 33, length 64 (ipip-proto-4) 10:58:03.553883 IP 172.16.0.67 > 172.16.0.66: IP 192.168.2.4 > 192.168.1.3: ICMP echo reply, id 4096, seq 33, length 64 (ipip-proto-4)
命令结果显示,Pod间的通信经由IPIP的三层隧道转发,外层IP首部中的IP地址为通信双方的节点IP(172.16.0.66和172.16.0.67),内层IP首部中的IP地址为通信双方的Pod IP(192.168.1.3和192.168.2.4)。相比较VxLAN的二层隧道来说,IPIP隧道的开销较小,但其安全性也更差一些。
需要提醒读者注意的是,tunl0接口的MTU默认为1440,这种设置主要是为适配Google的GCE环境,在非GCE的物理环境中,其最佳值为1480。因此,对于非GCE环境的部署,建议将配置清单calico.yaml下载至本地修改后,再将其应用到集群中。要修改的内容是DaemonSet资源calico-node的Pod模板,将容器calico-node的环境变量“FELIX_INPUTMTU”的值修改为1480即可,类似如下所示。图11-22给出了Calico部署于不同网络环境时不同部署方式适用的MTU大小。

图11-22 Calico于各网络环境上适用的MTU
对于50个节点以上规模的集群来说,所有Calico节点均基于Kubernetes API存取数据会为API Server带来不小的通信压力,这就应该使用calico-typha进程将所有Calico的通信集中起来与API Server进行统一交互。calico-typha以Pod资源的形式托管运行于Kubernetes系统之上,启用的方法为下载前面步骤中用到的Calico的部署清单文件至本地,修改其calico-typha的Pod资源副本数量为所期望的值并重新应用配置清单即可:
apiVersion: apps/v1beta1 kind: Deployment metadata: name: calico-typha ... spec: ... replicas: <number of replicas>
每个calico-typha Pod资源可承载100到200个Calico节点的连接请求,最多不要超过200个。另外,整个集群中的calico-typha的Pod资源总数尽量不要超过20个。
1.4.5 客户端工具calicoctl
Calico的二进制程序文件calicoctl可直接操作Calico存储来查看、修改或配置Calico系统特性,它可以运行为Kubernetes系统之上的Pod资源,也可直接以裸二进制文件部署于某管理主机之上,例如,kubectl所在的某主机以root用户的身份下载calicoctl文件并直接保存于/usr/bin/目录中:
~]# wget https://github.com/projectcalico/calicoctl/releases/download/v3.1.1/calicoctl \ -O /usr/bin/calicoctl ~]# chmod +x /usr/bin/calicoctl
calicoctl通过读写Calico的数据存储系统(datastore)进行查看或进行各类管理操作,通常,它需要提供认证信息经由相应的数据存储完成认证。使用Kubernetes API数据存储时,需要使用类似kubectl的认证信息完成认证。它可以通过环境变量声明的DATASTORE_TYPE和KUBECONFIG接入Kubernetes集群,例如以如下命令格式运行calicoctl:
~]$ DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get nodes
也可以直接将认证信息等保存于配置文件中,calicoctl默认加载/etc/calico/calicoctl.cfg配置文件读取配置信息。配置文件为yaml格式,语法极其类似于Kubernetes的资源配置清单:
apiVersion: projectcalico.org/v3 kind: CalicoAPIConfig metadata: spec: datastoreType: "kubernetes" kubeconfig: "/PATH/TO/.kube/config"
将上面示例配置中的/PATH/TO路径修改为相应的用户家目录即可,如/home/ik8s/。当然,也可以是用户自定义的其他kubeconfig配置文件的存放路径。
calicoctl的通用语法格式为“calicoctl[options]
~]$calicoctl node status
默认情况下,Calico的BGP网络工作于点对点的网格(node-to-node mesh)模型,它仅适用于较小规模的集群环境。中级集群环境应该使用全局对等BGP模型(Global BGP peers),以在同一二层网络中使用一个或一组BGP反射器构建BGP网络环境。而大型集群环境需要使用每节点对等BGP模型(Per-node BGP peers),即分布式BGP反射器模型,一个典型的用法是将每个节点都配置为自带BGP反射器接入机架顶部交换机上的路由反射器。
另外,读者也可以通过如下命令了解Calico当前IP地址池的相关设定,包括其地址范围,是否启用了IPIP模型等:
~]$ calicoctl get ipPool -o yaml apiVersion: projectcalico.org/v3 items: - apiVersion: projectcalico.org/v3 kind: IPPool metadata: …… spec: cidr: 192.168.0.0/16 ipipMode: Always natOutgoing: true ……
事实上,仅在那些不支持用户自定义BGP配置的网络中才需要使用IPIP的隧道通信类型。如果读者有一个自主可控的网络环境且部署规模较大时,可以考虑启用BGP的通信类型降低网络开销以提升传输性能,并且应该部署BGP反射器来提高路由学习效率。具体的实现方式请参考Calico站点上https://docs.projectcalico.org 给出的文档。
1.5 小结
本篇详细描述了Kubernetes的网络模型、CNI插件体系、主流的CNI插件flannel和Calico,并重点介绍了flannel和Calico的特性和应用方式,具体如下。
·Kubernetes的网络模型中包含容器间通信、Pod间通信、Service与Pod间的通信,以及集群外部流量与Pod间的通信四种通信需求。
·Kubernetes网络模型的实现通过CNI接口由外部网络插件来实现,如flannel、Calico和Canal等。
·flannel支持host-gw、VxLAN和UDP等后端,默认为VxLAN。
·网络策略能够给为Pod间提供通信隔离机制,它支持Ingress和Egress两种类型的规则。
·Calico是另一个流行的网络插件,它提供了高性能的适用于大规模网络模型的虚拟网络。
版权声明:如无特殊说明,文章均为本站原创,版权所有,转载需注明本文链接
本文链接:http://www.bianchengvip.com/article/Kubernetes-Network-Models-and-Network-Policies/