大家好,我是腾意。
资源监控系统是容器编排系统必不可少的组件,它为用户提供了快速了解系统资源分配和利用状态的有效途径,同时也是系统编排赖以实现的基础要件。在新一代监控架构体系中,Kubernetes将资源指标的规范及其实现分离开来,为用户提供了极大的扩展空间。本篇将主要说明如何为Kubernetes集群提供资源监控机制并利用资源指标。
1.1 资源监控及资源指标
监控应用程序的当前状态是帮助预测问题并发现生产环境中资源瓶颈的最有效方法之一,但它也是目前几乎所有软件开发组织面临的最大挑战之一,然而,微服务的日益普及使得日志记录和监控变得更加复杂,因为大量正在通信的应用程序本质上是分布式和多样化的,某个单点故障甚至可以中断整个系统,但识别它却变得越来越困难。
当然,监控只是微服务体系中众多挑战中的一个,此外,处理可用性、性能和应用部署等必然地推动了团队创建或使用编排工具来处理所有服务和主机,这也是Kubernetes这一类的编排系统迅速流行的原因之一,因为它能够处理多台计算机中的容器,并消除了处理分布式处理的复杂性。但这么一来问题又转为了如何有效地监控Kubernetes系统并输出指标数据。
众所周知,基于诸如CPU和内存使用等指标自动缩放工作负载规模的能力是Kubernetes最强大的功能之一。当然,要启用此功能,首先需要一种收集和存储这些指标的方法,曾经,这必然是指Heapster。不过,传统的基于Heapster收集的数据指标进行工作负载缩放的方法仅支持CPU一项指标,要扩展为支持多种指标可能有着不小的麻烦,并且来自于项目的各种贡献者的支持也不一致,因此它不久后可能会被淘汰。幸运的是,Kubernetes新的指标API实现了一种更为一致和高效的供给指标数据的方式,这为以自定义指标为基础的自动缩放目标提供了可行的实现。
1.1.1 资源监控及Heapster
Kubernetes有多个数据指标需要采集相关的数据,而这些指标大体上可以分为两个主要组成部分:监控集群本身和监控Pod对象。在集群监控层面,目标是监控整个Kubernetes集群的健康状况,包括集群中的所有工作节点是否运行正常、系统资源容量大小、每个工作节点上运行的容器化应用的数量以及整个集群的资源利用率等,它们通常可分为如下一些可衡量的指标。
1)节点资源状态:这个领域的众多指标都与资源利用状况有关,主要有网络带宽、磁盘空间、CPU和内存的利用率;基于这些度量指标,管理员能够评估集群规模的合理性。
2)节点数量:当今,众多公有云服务商均以客户使用实例数量计算费用,于是即时了解到集群中的可用节点数量可以为用户计算所需要支付的费用提供参考指标。
3)运行的Pod对象:正在运行的Pod对象数量能够用于评估可用节点的数量是否足够,以及在节点发生故障时它们是否能够承接整个工作负载。
另一方面,Pod资源对象的监控需求大体上可以分为三类:Kubernetes指标、容器指标和应用程序指标。
1)Kubernetes指标:用于监视特定应用程序相关的Pod对象的部署过程、当前副本数量、期望的副本数量、部署过程进展状态、健康状态监测及网络服务器的可用性等,这些指标数据需要经由Kubernetes系统接口获取。
2)容器指标:容器的资源需求、资源限制以及CPU、内存、磁盘空间、网络带宽等资源的实际占用状况等。
3)应用程序指标:应用程序自身内建的指标,通常与其所处理的业务规则相关,例如,关系型数据库应用程序可能会内建用于暴露索引状态有关的指标,以及表和关系的统计信息等。
监控集群所有节点的一种方法是通过DaemonSet控制器在各节点部署一个用于监控指标数据采集功能的Pod对象运行监控代理程序(agent),并在集群上部署一个收集各节点上由代理程序采集的监控数据的中心监控系统,统一进行数据的采集、存储和展示。这种部署方式给了管理员很大的自主空间,但也必定难以形成统一之势。
于是,Kubernetes系统特地于kubelet程序中集成相关的工具程序cAdvisor,用于对节点上的资源及容器进行实时监控及指标数据采集,支持的相关指标包括CPU、内存使用情况、网络吞吐量及文件系统使用情况等,并可通过TCP的4194端口提供一个Web UI(kubeadm的默认部署未启用此功能)。需要快速了解某特定节点上的cAdvisor运行是否正常,以及了解单节点的资源利用状态时,可直接访问cAdvisor Web UI,URL是http://<Node_IP>:4194/ ,其默认的界面如图14-1所示。

图14-1 cAdvisor图形面板
cAdvisor的问题同样在于其仅能收集单个节点及其相关Pod资源的相关指标数据。事实上,将各工作节点采集的指标数据予以汇集并通过一个统一接口向外暴露不仅能为用户带去便捷,而且也是Kubernetes系统某些组件所依赖的底层功能,这些组件包括kubectl top命令、Horizontal Pod Autoscalers(即HPA)资源以及Dashboard的某些功能等。
~]$ kubectl top nodes Error from server (NotFound): the server could not find the requested resource (get services http:heapster:)
Heapster是这类项目的一个著名实现,用于为集群提供指标API及其实现,并进行系统监控,而且它曾与ClusterDNS、Ingress和Dashboard一起并称为Kubernetes的四大核心附件,其组件结构如图14-2所示。
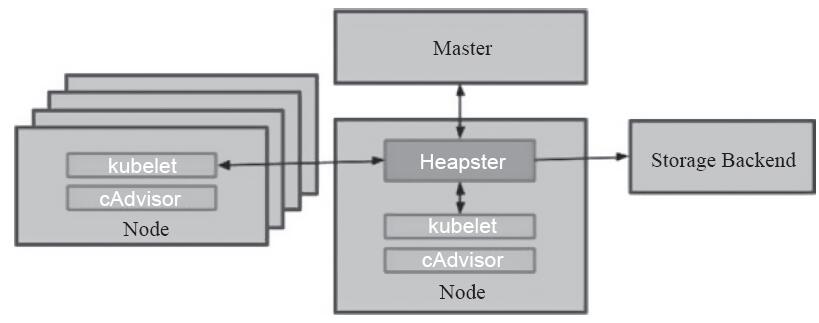
图14-2 Heapster系统数据流向
Heapster是集群级别的监视和事件数据聚合工具,它原生支持并且适用于所有方式构建的Kubernetes集群系统。Heapster本身可作为集群中的一个Pod对象运行,它通过发现集群中的所有节点实现从每个节点kubelet内建的cAdvisor获取性能和指标数据,并通过标签将Pod对象及其相关的监控数据进行分级、聚合后推送到可配置的后端存储系统进行存储和可视化。
功能完备的Heapster监控系统流行的解决方案是由InfluxDB作为存储后端,Grafana为可视化接口,而Heapster从各节点的cAdvisor采集数据并存储于InfluxDB中,由Grafana进行展示。托管于Kubernetes集群中的InfluxDB、Grafana和Heapster运行为常规的Pod资源对象,它们彼此之间通过环境变量及服务发现功能自动协同。另外,它还支持其他多种后端,如OpenTSDB、Elasticsearch、Log、Monasca、Kafka、Riemann和Hawkular-Metrics等,可按需灵活组合出多种不同的监控解决方案。
然而,Heapster支持的每个存储后端的代码都直接驻留在其代码仓库中成为核心代码库的一部分,结果是必然会被烂尾的驻留代码所拖累,这甚至是成为了用户使用Heapster最常见的挫败原因。更重要的是,即使Heapster没有将Prometheus作为数据接收器,却又暴露了Prometheus格式的指标,这通常会引起不小的混淆和麻烦。
换句话说,Heapster既为那些依赖于指标数据的系统组件提供了指标API(非标准格式的一等类别Kubernetes API),同时又提供了指标API接口背后的实现方式,即收集和存储指标数据以响应对API的请求。这种以耦合度较高的方式实现核心系统组件依赖到的功能部件的做法对系统的变迁引入了不少的不确定性和隐患。
另外,Heapster假设数据存储是一个原始的时间序列数据库,这些数据库都有着一个可直接写入路径。这使得它与Prometheus系统基本上不相兼容,因为Prometheus工作为拉取式模型。然而,Kubernetes生态系统的整体组件几乎原生支持Prometheus系统,于是,Heapster的这部分功能逐渐被其所取代。
为了避免重蹈Heapster的覆辙,资源指标API(resource metrics api)和自定义指标API(custom metrics api)被有意地创建为纯粹的API定义而非具体的实现,它们作为聚合的API安装到Kubernetes集群中,从而允许在API保持不变的情况下切换其具体的实现方案,这一点极大地降低了二者的耦合级别。最终,Heapster用于提供核心指标API的功能也被聚合方式的指标API服务器metrics-server所取代。
1.1.2 新一代监控架构
Kubernetes如此强大的原因之一便是其灵活的可扩展性,其中表现得尤为抢眼的是,它通过API聚合器为开发人员提供了轻松扩展API资源的能力,Kubernetes在1.7版本中引入的自定义指标API(custom metrics API),以及在1.8版本中引入的资源指标API(resource metrics API,简称为指标API)都属于这种类型的扩展。
资源指标API主要供核心系统组件使用,如调度程序、HPA和“kubectl top”命令等,虽然是以扩展方式实现API,但它提供的是kubernetes系统必备的“核心指标”,因此不适用于与第三方监控系统集成,如Prometheus等。另一方面,自定义指标API则为用户提供了自行按需扩展指标的接口,它允许用户自定义指标类型的API Server并直接聚合进主API Server中,因此具有更广泛的使用场景。简单总结起来就是,新一代的Kubernetes监控系统架构主要由核心指标流水线和监控指标流水线协同组成,具体如下。
(1)核心指标流水线
由kubelet、资源评估器、metrics-server以及由API Server提供的API群组(由APIService对象提供)组成,如图14-3所示,它们可用于为Kubernetes系统提供核心指标,从而能够了解并操作其内部组件和核心程序。截至目前,相关的指标主要包括CPU累计使用、内存即时使用率、Pod的资源占用率及容器的磁盘占用率等几个。所用到的度量标准核心系统组件包括调度逻辑(基于指标数据的调度程序和应用规模的水平缩放),以及部分UI组件(如kubectl top命令和Dashboard)等。
(2)监控指标流水线
监控指标流水线用于从系统收集各种指标数据并提供给终端用户、存储系统以及HPA控制器等使用,它收集的数据指标也称为非核心指标,但它们通常也包含核心指标(未必是Kubernetes可以理解的格式)以及其他指标。自定义指标API允许用户扩展任意数量的特定于应用程序的指标,例如,其指标可能包括队列长度和每秒入口请求数等。Kubernetes系统本身不会提供此类组件,也不会对这些指标提供相关的解释,它有赖于用户按需选择使用的第三方解决方案。自定义指标API系统组件如图14-4所示。
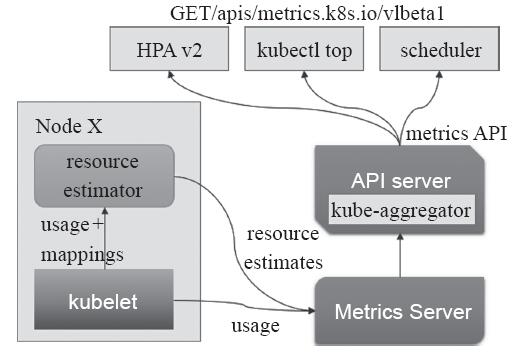
图14-3 资源指标API系统组件
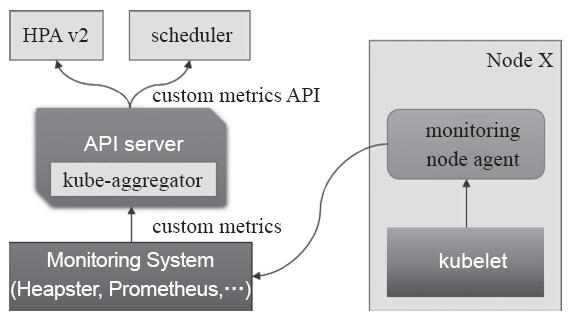
图14-4 自定义指标API系统组件
一个能同时使用资源指标API和自定义指标API的组件是第二版的HorizontalPod-Autoscaler控制器(HPAv2),它实现了基于观察到的指标自动缩放Deployment或ReplicaSet 类型控制器管控下的Pod副本数量。HPA的第一个版本只能根据观察到的CPU利用率进行扩展,尽管在某些情况下很有用,但CPU并不总是最适合自动调整应用程序的度量指标。
从根本上来讲,资源指标API和自定义指标API都仅是API的定义和规范,它们自身都并非具体的API实现。目前,资源指标API的实现较主流是的metrics-server,而自定义指标API则以建构在监控系统Prometheus之上的k8s-prometheus-adapter最广为接受。事实上,Prometheus也是CNCF旗下的项目之一,并且得到了Kubernetes系统上众多组件的原生支持。
1.2 资源指标及其应用
如前所述,自Kubernetes 1.8版本起,诸如容器的CPU和内存资源占用状况一类的资源利用率指标可由客户端通过指标API直接调用,这些客户端包括但不限于终端用户、kubectl top命令和HPA(v2)等。另外,尽管通过指标API能够查询某节点或Pod的当前资源占用情况,但API本身并不存储任何指标数据,因此,它仅提供资源占用率的实时监测数据而无法提供过去指定时刻的指标监测记录结果。
1.2.1 部署metrics-server
事实上,资源指标API与系统的其他API并无特别不同之外,它通过API Server的URL路径/apis/metrics.k8s.io/进行存取,并提供同样级别的安全性、稳定性及可靠性保证。不过,只有在Kubernetes集群中部署Metrics Server(指标服务器)应用之后,指标API方才可用。资源指标API架构简图如图14-5所示。
Metrics Server是集群级别的资源利用率数据的聚合器(aggregator),它的创建于不少方面都受到了Heapster的启发,且于功能和特性上完全可被视作一个仅服务于指标数据的简化版的Heapster。Metrics Server通过Kubernetes聚合器(kube-aggregator)注册到主API Server之上,而后基于kubelet的Summary API收集每个节点上的指标数据,并将它们存储于内存中然后以指标API格式提供,如图14-6所示。
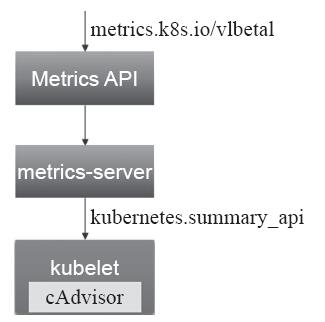
图14-5 资源指标API架构简图

图14-6 聚合metrics-server于主API Server上
Metrics Server基于内存存储,重启后数据将全部丢失,而且它仅能留存最近收集到的指标数据,因此,如果用户期望访问历史数据,就不得不借助于第三方的监控系统(如Prometheus等),或者自行开发以实现其功能。
Metrics Server是Kubernetes多个核心组件的基础依赖,因此,它应该默认部署运行于集群中。一般说来,Metrics Server在每个集群中仅会运行一个实例,启动时,它将自动初始化与各节点的连接,因此出于安全方面的考虑,它需要运行于普通节点而非Master主机之上。直接使用项目本身提供的资源配置清单即能轻松完成metrics-server的部署,下面就来分步说明其实施步骤。
(1)克隆项目代码的仓库至本地目录以获得其资源配置清单
~]$git clone https://github.com/kubernetes-incubator/metrics-server.git
注意,截至目前,metrics-server程序默认会从kubelet的基于HTTP通信的10255端口获取指标数据,但出于安全通信的目的,Kubernetes 1.11版本的kubeadm在初始化集群时会关掉kubelet基于HTTP的10255端口,从而导致其部署完成后无法正常获取数据。另外,代码仓库中的部署清单文件deploy/1.8+/metrics-server-deployment.yaml中并未明确为主程序/metrics-server传递参数指定指标数据的获取接口,它通常应该是kubernetes.summary_api。因此,在启动部署操作之前,需要修改此清单文件,下面在metrics-server容器配置段中添加如下内容:
command: - /metrics-server - --source=kubernetes.summary_api:https://kubernetes.defaultkubeletHttps=true &kubeletPort=10250&insecure=true
Metrics Server项目处于非常活跃的维护状态,其相应的代码仓库或许在读者读到此书时便已完成了修正,因此建议进行metrics-server部署时先不做修改,待部署后观测到连接kubelet错误一类的信息时再予以手动更正。
(2)基于资源配置清单完成相应资源的创建
~]$ kubectl apply -f metrics-server/deploy/1.8+/
各部署清单会于kube-system名称空间中创建出多个类型的资源对象,包括RBAC相关的rolebinding、clusterrole和clusterrolebinding对象,以及serviceaccount对象用于在启用了RBAC授权插件的集群上完成对metrics-server开放资源访问的许可。另外,它还会通过一个APIService对象创建Metrics API相关的群组从而将metrics-server提供的API聚合进主API Server上。因此,接下来要检验相应的API群组metrics.k8s.io是否出现在Kubernetes集群的API群组列表中:
~]$ kubectl api-versions | grep metrics metrics.k8s.io/v1beta1
(3)确认相关的Pod对象运行正常
首先检查metrics-server的Pod对象是否处于“Running”状态:
~]$ kubectl get pods -n kube-system -l k8s-app=metrics-server NAME READY STATUS RESTARTS AGE metrics-server-778ddc45b5-hvwdh 1/1 Running 0 7m
而后检查Pod中的容器其日志信息中是否出现错误提示:
~]$ kubectl logs metrics-server-778ddc45b5-hvwdh -n kube-system
(4)检查资源指标API的可用性
“kubectl get--raw”命令可用于基于资源URL路径测试资源指标API服务的可用状态,例如以下命令应返回集群中所有节点的资源使用情况指标列表,它能够列出集群中所有节点的CPU及内存资源占用情况。在使用时,也可以直接给定具体的节点标识,从而仅列出特定节点的相关信息:
~]$ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq . { "kind": "NodeMetricsList", "apiVersion": "metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/metrics.k8s.io/v1beta1/nodes" }, …… }
注意 jq是专用于处理JSON数据的命令行工具,其功能类似于sed对文本信息的处理,在CentOS系统上由jq程序包所提供。
此外,Pod对象的资源消耗信息也可以经由资源指标API直接列出,例如,要获取集群上所有Pod对象的相关资源消耗数据,可使用如下格式的命令:
~]$ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq
资源指标API支持HPA v2控制器根据资源指标(如CPU和内存使用量)进行扩展,但不支持使用特定于应用程序的指标,那些特定于应用程序的指标需要依赖于自定义指标API。执行完成上述步骤并确认结果无误后,metrics-server即成功部署完成,那些依赖于核心资源指标的控制器、调度器及UI工具也将在功能上得到进一步的完善。
1.2.2 kubectl top命令
kubectl top命令可显示节点和Pod对象的资源使用信息,它依赖于集群中的资源指标API来收集各项指标数据。它包含有node和pod两个子命令,可分别用于显示Node对象和Pod对象的相关资源占用率。
列出Node资源占用率命令的语法格式为“kubectl top node[-l label|NAME]”,例如下面显示所有节点的资源占用状况的结果中显示了各节点累计CPU资源占用时长及百分比,以及内容空间占用量及占用比例。必要时,也可以在命令中直接给出要查看的特定节点的标识,以及使用标签选择器进行节点过滤:
~]$ kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% master.ilinux.io 444m 11% 1127Mi 65% node01.ilinux.io 158m 3% 558Mi 32% ……
而名称空间级别的Pod对象资源占用率的使用方式会略有不同,使用时,一般应该限定名称空间及使用标签选择器过滤出目标Pod对象。命令的语法格式为“kubectl top pod[NAME|-l label][--all-namespaces][--containers=false|true]”,例如,下面显示kube-system名称空间中标签为“k8s-app=kube-dns”的所有Pod资源及其容器的资源占用状态:
~]$ kubectl top pod -l k8s-app=kube-dns --containers=true -n kube-system POD NAME CPU(cores) MEMORY(bytes) coredns-78fcdf6894-ncxdj coredns 3m 18Mi coredns-78fcdf6894-pvv88 coredns 3m 17Mi
kubectl top命令为用户提供了简洁、快速获取Node对象及Pod对象占用系统资源状况的接口,是集群运行和维护的常用命令之一。
1.3 自定义指标与Prometheus
除了资源指标之外,用户或管理员需要了解的指标数据还有很多,如Kubernetes指标、更全面的容器指标、更全面的节点资源指标及应用程序指标,等等。自定义指标API允许请求任意指标,其指标API的实现要特定于相应的后端监视系统。Prometheus是第一个开发了相应适配器的监控系统,毕竟它是监控Kubernetes的第一选择。这个适用于Prometheus的Kubernetes Custom Metrics Adapter由托管在GitHub上的k8s-prometheus-adapter项目提供,如图14-7所示。
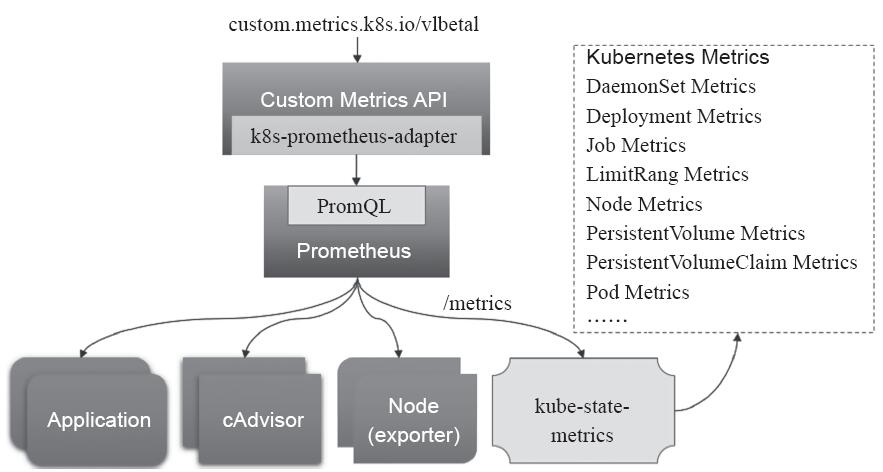
图14-7 自定义指标
自定义指标API的目的是提供最终用户和Kubernetes系统组件可以依赖的稳定的、版本化的API,但其可用的实现及可用指标则有赖于第三方或用户的自行实现,目前基于Prometheus收集和存储指标数据,并借助于k8s-prometheus-adapter将这些指标数据查询接口转换为标准的Kubernetes自定义指标是较为流行的解决方案之一。
1.3.1 Prometheus概述
Prometheus是一个开源的服务监控系统和时序数据库,由社交音乐平台SoundCloud在2012年开发,也是CNCF除Kubernetes之外收录的第二款产品,目前已经成为Kubernetes生态圈中的核心监控系统,而且越来越多的项目(如etcd等)都提供了对Prometheus的原生支持,这足以证明社区对它的认可程度。
Prometheus提供了通用的数据模型和便捷的数据采集、存储和查询接口。其核心组件Prometheus服务器定期从静态配置的监控目标(targets)或者基于服务发现(service discovery)自动配置的目标中拉取数据,新拉取到的数据大于配置内存缓存区时,数据将持久化到存储设备中,包括远程云端存储系统。Prometheus的生态组件架构如图14-8所示。
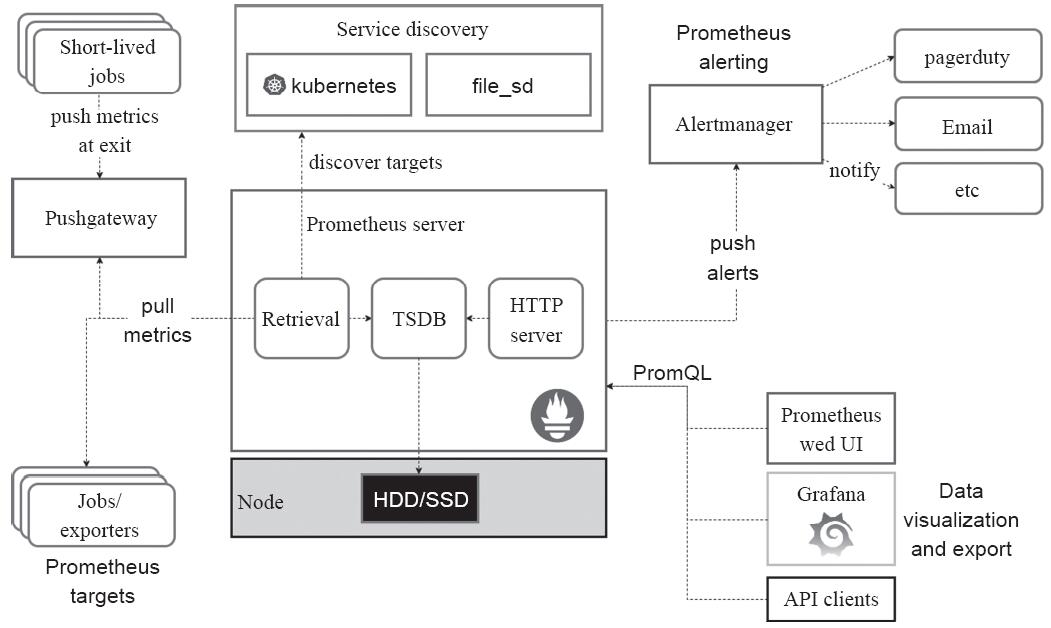
图14-8 Prometheus的生态组件架构
图14-8所示的各种组件中,每个被监控的目标(主机、应用程序等)都可通过专用的exporter程序提供输出监控数据的接口,并等待Prometheus服务器周期性的数据抓取操作。若存在告警规则,则抓取到数据后会检查并根据规则进行计算,满足告警条件即会生成告警,并发送到Alertmanager完成告警的汇总和分发等操作。被监控目标有主动推送数据的需求时,可部署Pushgateway组件接收并临时存储数据,并等待Prometheus服务器完成数据采集。
任何被监控的目标都需要事先纳入到监控系统中才能进行时序数据采集、存储、告警及相关的展示等,监控目标既可以通过配置信息以静态形式指定,也可以让Prometheus通过服务发现机制动态管理(增删等),对于变动频繁的系统环境(如容器云环境)来说,这种动态管理机制尤为有用。在Kubernetes集群及相关的环境中,除了此前配置的从Pod对象中的容器应用获得资源指标数据以外,Prometheus还支持通过多个监控目标采集Kubernetes监控架构体系中所谓的“非核心指标数据”,如图14-9所示。

图14-9 Kubernetes中的Prometheus数据源
1)监控代理程序,如node_exporter,
收集标准的主机指标数据,包括平均负载、CPU、Memory、Disk、Network及诸多其他维度的数据,独立的指标可能多达上千个。
2)kubelet(cAdvisor):收集容器指标数据,它们也是所谓的Kubernetes“核心指标”,每个容器的相关指标数据主要有CPU利用率(user和system)及限额、文件系统读/写限额、内存利用率及限额、网络报文发送/接收/丢弃速率等。
3)API Server:收集API Server的性能指标数据,包括控制工作队列的性能、请求速率与延迟时长、etcd缓存工作队列及缓存性能、普通进程状态(文件描述符、内存、CPU等)、Golang状态(GC、内存和线程等)。
4)etcd:收集etcd存储集群的相关指标数据,包括领导节点及领域变动速率、提交/应用/挂起/错误的提案次数、磁盘写入性能、网络与gRPC计数器等。
5)kube-state-metrics:此组件能够派生出Kubernetes相关的多个指标数据,主要是资源类型相关的计数器和元数据信息,包括指定类型的对象总数、资源限额、容器状态(ready/restart/running/terminated/waiting)以及Pod资源的标签系列等。
Prometheus能够直接把Kubernetes API Server作为服务发现系统使用进而动态发现和监控集群中的所有可被监控的对象。这里需要特别说明的是,Pod资源需要添加下列注解信息才能被Prometheus系统自动发现并抓取其内建的指标数据。
1)prometheus.io/scrape:用于标识是否需要被采集指标数据,布尔型值,true或false。
2)prometheus.io/path:抓取指标数据时使用的URL路径,一般为/metrics。
3)prometheus.io/port:抓取指标数据时使用的套接字端口,如8080。
另外,仅期望Prometheus为后端生成自定义指标时仅部署Prometheus服务器即可,它甚至也不需要数据持久功能。但若要配置完整功能的监控系统,管理员还需要在每个主机上部署node_exporter、按需部署其他特有类型的exporter以及Alertmanager。
1.3.2 部署Prometheus监控系统
为了便于用户快速集成一个完整的Prometheus监控环境,Kubernetes源代码的集群附件目录中统一提供了Prometheus、Alertmanager、node_exporter和kube-state-metrics相关的配置清单,路径为cluster/addons/prometheus,每个项目的配置清单不止一个且文件都以项目名称开起。将Kubernetes源码仓库克隆至本地,以便在后面的各配置步骤中应用其配置文件:
~]$git clone https://github.com/kubernetes/kubernetes.git
为了便于读者理解和排除问题,下面分步骤分别说明kube-state-metrics、node_exporter、Alertmanager和Prometheus四个组件的部署过程。
1.生成集群资源状态指标
kube-state-metrics能够从Kubernetes API Server上收集各大多数资源对象的状态信息并将其转为指标数据,它工作于HTTP的/metrics接口,通过Prometheus的Go语言客户端暴露于外,Prometheus系统以及任何兼容相关客户端接口的数据抓取工具都可采集相关数据,并予以存储或展示。因此,再结合Prometheus的其他指标数据采集接口及报警功能,用户可于Kubernetes构建出一个自定义指标API Server的同时提供一个完整的监控系统。
kube-state-metrics是Kubernetes集群的一个附加组件,它通过Kubernetes API service监听资源对象的状态并生成相关的指标,不过,它不在意单个Kubernetes组件的运行状况,而是关注内部各种对象的整体运行状况,如Deployment对象或ReplicaSet对象等。换句话说,kube-state-metrics的重点是从Kubernetes的对象状态生成全新的指标。
最初,kube-state-metrics是作为Heapster的另一个指标数据源而开发的,Heapster只需要获取、格式化和转发原本就存在的指标,特别是Kubernetes组件的指标,并将它们写入接收器即可。相比之下,kube-state-metrics在内存中保存了Kubernetes系统状态的完整快照,并不断生成基于它的新指标,但不负责在任何地方导出指标,那是Heapster的任务。
不过,有些监控系统(如Prometheus)根本不使用Heapster进行指标数据收集,而是自我实现了特有的收集方式,因此,将kube-state-metrics作为单独的项目,可以让Prometheus这类监视系统访问也能使用由它提供的指标。目前,kube-state-metrics主要负责为CronJob、Deployment、PersistentVolumeClaim等各类型的资源对象生成指标数据,各类资源类型生成的指标的功能及用法请参考相关的文档,地址为 https://github.com/kubernetes/kube-state-metrics/tree/master/Documentation 。
将工作目录切换到克隆至本地的Kubernetes项目源码的cluster/addons/prometheus目录中,将所有文件名以kube-state-metrics相关的配置清单创建于集群中即能完成部署:
~]$ cd kubernetes/cluster/addons/prometheus/ ~]$ for file in kube-state-*; do kubectl apply -f $file; done
部署完成后会于kube-system名称空间创建一个名为kube-state-metrics的Deployment控制器对象,其所生成的Pod对象中的容器应用将监听于8080和8081端口以提供指标数据,除此之外,还会在kube-system名称空间中创建一个同名的Service对象为客户端提供固定的访问入口,用户也可以通过任何类型的HTTP客户端程序测试访问其原始格式的指标及数据。例如,启动一个Pod客户进行访问测试,命令如下:
~]$ kubectl run client-$RANDOM --image=cirros -it --rm -- sh / # curl -s kube-state-metrics.kube-system:8080/metrics | tail # HELP kube_service_spec_type Type about service. # TYPE kube_service_spec_type gauge kube_service_spec_type{namespace="default",service="kubernetes",type="ClusterIP"} 1 ……
分别通过8080和8081端口进行确认能各自得到一系列的指标数据,即表示kube-state-metrics准备就绪。
2.Exporter及Node Exporter
Prometheus通过HTTP周期性抓取指标数据,监控目标上用于接收并响应数据抓取请求的组件统称为exporter。目前,Prometheus项目及社区提供了众多现成可用的exporter,分别用于监控操作系统、数据库、硬件设备、消息队列、存储系统等类型的多种目标对象。
提示 Prometheus的常用exporter列表位于https://prometheus.io/docs/instrumenting/exporters/ 。
在监控目标系统上,Exporter将收集的数据转化为文本格式,并通过HTTP对外暴露相应的接口,它不会局限于任何编程语言或实现方式,只需要它能够接收来自Prometheus服务器端的数据抓取请求,并以特定格式的数据进行响应,因此它尤其适用于容器环境。
·Exporter的响应内容以行为单位,其中,以“#HELP”开头的是注释信息用于提供指标说明,以“#TYPE”开头的注释行用于指明当前指标的类型,它可以是counter、gauge、histogram或summary其中之一;空白行将被忽略。
·每一个非注释行都是一个键值类型的数据,其键即是指标,相应的值是当前指标本次响应的float类型的数据;若返回的值有两个,则最后一个会被当作时间戳;响应值必须要用双引号进行引用,否则即为格式错误。
Prometheus为监控类UNIX操作系统提供了一个专用的node_exporter程序,它能够收集多种系统级指标,如conntrack、cpu、diskstats、meminfo、filesystem、netstat和socketstats等数十种。node_exporter运行为守护进程监听于节点上的9100端口,通过URL路径/metrics提供指标数据,Prometheus服务器可在配置文件中使用静态配置监控每一个运行node_exporter的目标主机,也能够使用基于文件、Consul、DNS、Kubernetes等多种服务发现机制动态添加监控对象。
事实上,监控Kubernetes集群时,每个节点本身就能通过kubelet或cAdvisor提供符合Prometheus规范的节点指标数据,因此也可以不安装node_exporter程序,甚至Kubernetes为部署Prometheus服务器提供的配置清单中也没有加载各节点exporter上的指标。不过,用户也完全可以部署并自行配置通过node_exporter进程节点进行监控。
在此前克隆的Kubernetes源码目录的cluster/addons/prometheus路径下执行如下命令便可完成在集群中各节点上部署并运行node_exporter,它将以DaemonSet控制器对象于各节点中运行一个相应的Pod资源:
~]$ cd kubernetes/cluster/addons/prometheus/ ~]$ for file in node-exporter-*; do kubectl apply -f $file; done
node_exporter相关的各Pod对象共享使用其所在节点的网络名称空间,它直接监听于相关地址的9100端点,因此可直接对其中某一个节点发起请求测试:
~]$ curl node01.ilinux.io:9100/metrics …… # HELP process_virtual_memory_bytes Virtual memory size in bytes. # TYPE process_virtual_memory_bytes gauge process_virtual_memory_bytes 1.38784768e+08
上面显示的命令响应结果中,指标名称为process_virtual_memory_bytes,相应值为float格式,前面两行分别是帮助信息及指标类型说明。
3.告警系统Alertmanager
Prometheus的告警功能由两个步骤实现,首先是Prometheus服务器根据告警规则将告警信息发送给Alertmanager,而后由Alertmanager对收到的告警信息进行处理,包括去重、分组并路由到告警接收端,支持的形式包括slack、email、pagerduty、hitchat和WebHook等接口上的联系人信息。
下面的配置文件片断取自kubernetes源码目录中的cluster/addons/prometheus/alertmanager-configmap.yaml文件,它是一个ConfigMap对象,用于为运行于Pod中的Alertmanager提供配置信息:
global: null receivers: - name: default-receiver route: group_interval: 5m group_wait: 10s receiver: default-receiver repeat_interval: 3h
上面的配置信息非常简洁,全局配置参数(global)为空,告警接收端(receivers)只有一个default-receiver,路由(route)逻辑是将告警信息暂存5分钟后进行发送,且每隔3小时重复一次。实际应用中需要提供的配置请读者参考Alertmanager的相关文档。
Prometheus附件的配置清单中,Alertmanager的Deployment对象配置容器使用了持久存储卷,它定义在Pod模板中,存储卷类型为persistentVolumeClaim,因此部署前需要确保能为其提供使用的存储卷。
另外,Alertmanager的守护进程通过9093端口提供了一个Web UI,用于检查和过滤告警信息。如需于Kubernetes集群之外访问此接口,这里选择将其Service对象设定为NodePort类型,并绑定固定的30093端口,配置片断如下所示:
spec: ports: - name: http port: 80 protocol: TCP targetPort: 9093 nodePort: 30093 selector: k8s-app: alertmanager type: "NodePort"
待条件满足后,即可部署Alertmanager:
~]$ cd kubernetes/cluster/addons/prometheus/ ~]$ for file in node-exporter-*; do kubectl apply -f $file; done
部署完成后打开其Web UI即可过滤和查看告警信息,主界面如图14-10所示。

图14-10 Alertmanager的Web UI
4.部署Prometheus服务器
Prometheus服务器是整个监控系统的核心,它通过各exporter周期性采集指标数据,存储于本地的TSDB(Time Series Database)后端存储系统中,并通过PromQL向客户端提供查询接口。
由Kubernetes项目提供的附件配置清单中,Prometheus使用StatefulSet配置对象,各Pod对象通过volumeClaimTemplates对象申请使用持久存储卷,因此部署前需要确保能为其提供使用的存储卷。另外,Prometheus也提供了Web UI,通过9090端口输出,测试使用时,可以配置其通过NodePort类型的Service对象进行输出:
~]$ cd kubernetes/cluster/addons/prometheus/ ~]$ for file in prometheus-*; do kubectl apply -f $file; done
确认各相关资源对象得以正确创建,且相关的Pod都能正常运行无误后即完成部署。此时,于Prometheus的Web GUI的Targets状态页面中可看到相关节点的发现结果,如图14-11所示。
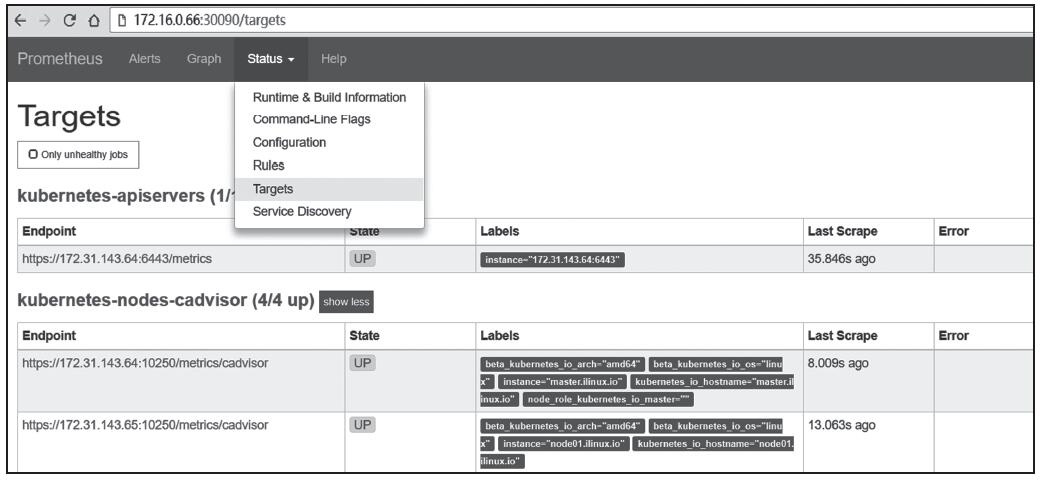
图14-11 Prometheus的监控目标
PromQL(Prometheus Query Language)是Prometheus专有的数据查询语言(DSL),其提供了简洁且贴近自然语言的语法实现了时序数据的分析计算能力。PromQL表现力丰富,支持条件查询、操作符,并且内建了大量内置函数,可供客户端针对监控数据的各种维度进行查询。PromQL的使用方式请参考相关的文档或书籍。
1.3.3 自定义指标适配器k8s-prometheus-adapter
Prometheus提供的PromQL接口无法直接作为自定义指标数据源,它并非Kubernetes系统的聚合API服务器,它们之间还需要一个中间层“Kubernetes Custom Metrics Adapter for Prometheus”,目前最流行的自定义指标适配器是托管于Github之上的k8s-prometheus-adapter项目。
自定义的Kubernetes API Server必须要基于HTTPS与客户端进行通信,因此为了便于部署,这些程序大多数会生成一个自签证书。不过,k8s-prometheus-adapter项目提供的配置清单要使用一个名为cm-adapter-serving-certs的Secret对象加载由用户自行提供的证书。于是,部署之前需要以合理的方式生成证书并配置为Secret对象。这里选择以Master主机系统管理员的身份基于Kubernetes的CA为其签署一个自制证书:
~]# cd /etc/kubernetes/pki/ ~]# (umask 077; openssl genrsa -out serving.key 2048) ~]# openssl req -new -key serving.key -out serving.csr -subj "/CN=serving" ~]# openssl x509 -req -in serving.csr -CA /etc/kubernetes/pki/ca.crt \ -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out serving.crt -days 3650
k8s-prometheus-adapter默认会部署在custom-metrics名称空间,因此需要将相关证书和私钥作为此名称空间中的Secret对象。
注意 证书和私钥两个数据项的相应键名必须为serving.crt和serving.key。
~]$ kubectl create namespace custom-metrics ~]$ kubectl create secret generic cm-adapter-serving-certs -n custom-metrics \ --from-file=serving.crt=./serving.crt --from-file=serving.key=./serving.key
确认创建完成后即可部署k8s-prometheus-adapter,部署清单位于项目源代码的deploy目录中。克隆到相关的代码并将资源创建于集群中即可:
~]$ git clone https://github.com/DirectXMan12/k8s-prometheus-adapter.git ~]$ kubectl apply -f k8s-prometheus-adapter/deploy/manifests/
资源创建过程中会在kube-aggregator上注册新的API群组custom.metrics.k8s.io,待相关的Pod对象转为正常运行状态之后即可通过kubectl api-versions命令确认其API接口注册的结果:
~]$ kubectl api-versions | grep custom custom.metrics.k8s.io/v1beta1
向custom.metrics.k8s.io群组直接发送请求即可列出其可用的所有自定义指标,例如,这里使用“kubectl get--raw”命令进行测试,并使用jq命令过滤结果,仅列出指标名称:
~]$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq '.resources[].name' "pods/kube_pod_container_status_running" "pods/kube_pod_info" ……
另外,也可以直接通过API查看指定的Pod对象的相应指标及其值,例如,可以使用类似如下的命令列出kube-system名称空间中的所有Pod对象的文件系统占用率:
~]$ kubectl get --raw \ "/apis/custom.metrics.k8s.io/v1beta1/namespaces/kube-system/pods/*/memotry_usage_ bytes" | jq .
上面的命令会列出相应名称空间中所有Pod对象的内存资源占用状况,一个数据项的显示结果足以了解其响应格式,例如下面的内容截取自命令结果中关于coredns的Pod对象的相关输出:
{ "describedObject": { "kind": "Pod", "namespace": "kube-system", "name": "coredns-78fcdf6894-cftl9", "apiVersion": "/__internal" }, "metricName": "memory_usage_bytes", "timestamp": "2018-08-28T04:54:32Z", "value": "40189952" }
1.4 自动弹性缩放
Deployment、ReplicaSet、Replication Controller或StatefulSet控制器资源管控的Pod副本数量支持手动方式的运行时调整,从而更好地匹配业务规模的实际需求。不过,手动调整的方式依赖于用户深度参与监控容器应用的资源压力并且需要计算出合理的值进行调整,存在一定程度的滞后性。为此,Kubernetes提供了多种自动弹性伸缩(Auto Scaling)工具,具体如下。
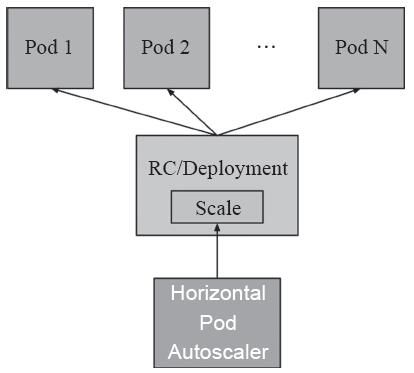
图14-12 HPA控制器示意图
·HPA:全称Horizontal Pod Autoscaler,一种支持控制器对象下Pod规模弹性伸缩的工具,目前有两个版本的实现,分别称为HPA和HPA(v2),前一种仅支持把CPU指标数据作为评估基准,而新版本支持可从资源指标API和自定义指标API中获取的指标数据。HPA控制器示意图如图14-12所示。
·CA:全称Cluster Autoscaler,是集群规模自动弹性伸缩工具,能自动增减GCP、AWS或Azure
·集群上部署的Kubernetes集群的节点数量,GA版本自Kubernetes 1.8起可用。
·VPA:全称Vertical Pod Autoscaler,是Pod应用垂直伸缩工具,它通过调整Pod对象的CPU和内存资源需求量完成扩展或收缩,目前仍处于alpha阶段。
·AR:全称Addon Resizer,是一个简化版本的Pod应用垂直伸缩工具,它基于集群中的节点数量来调整附加组件的资源需求量,当前仍处于beta级别。
1.4.1 HPA概述
尽管Cluster Autoscaler高度依赖基础云计算环境的底层功能,但HPA、VPA和AR可以独立于IaaS或PaaS云环境运行。HPA可作为Kubernetes API资源和控制器实现,它基于采集到的资源指标数据来调整控制器的行为,控制器会定期调整ReplicaSets或Deployment控制器对象中的副本数,以使得观察到的平均CPU利用率与用户指定的目标相匹配。
HPA自身是一个控制循环(control loop)的实现,其周期由controller-manager的--horizontal-pod-autoscaler-sync-period选项来定义,默认为30秒。在每个周期内,controller-manager将根据每个HPA定义中指定的指标查询相应的资源利用率。controller-manager从资源指标API(针对每个Pod资源指标)或自定义指标API(针对所有其他指标)中获取指标数据。
·对于每个Pod资源指标(如CPU),控制器都将从HPA定位到的每个Pod的资源指标API中获取指标数据。若设置了目标利用率(target utilization)标准,则HPA控制器会计算其实际利用率(utilized/requests)。若设置的是目标原始值,则直接使用原始指标值。然后控制器获取所有目标Pod对象的利用率或原始值的均值(取决于指定的目标类型),并生成一个用于缩放所需副本数的比率。不过,对于未定义资源需求量的Pod对象,HPA控制器将无法定义该容器的CPU利用率,并且不会为该指标采取任何操作。
·对于每个Pod对象的自定义指标,HPA控制器的功能与每个Pod资源指标的处理机制类似,只是它仅能够处理原始值而非利用率。
不过,使用HPA控制器管理Pod对象副本规模时,由于所评估指标的动态变动特性,副本数量可能会频繁波动,这种现象有时也称为“抖动”。从Kubernetes 1.6版本开始,集群管理员可以通过调整kube-controller-manager的选项值定义其变动延迟时长来缓解此问题。目前,默认的缩容延迟时长为5分钟,而扩容延迟时长为3分钟。
HPA控制器可以通过两种不同的方式获取指标:Heapster和REST客户端接口。使用直接Heapster获取指标数据时,HPA直接通过API服务器的服务代理子资源向Heapster发起查询请求,因此,Heapster需要事先部署在群集上并在kube-system名称空间中运行。使用REST客户端接口获取指标时,需要事先部署好资源指标API及其API Server,必要时,还应该部署好自定义指标API及其相关的API Server。
HPA是Kubernetes autoscalingAPI群组中的API资源,当前的稳定版本仅支持CPU自动缩放,它位于autoscaling/v1群组中。而测试版本包含对内存和自定义指标的扩展支持,测试版本位于API群组autoscaling/v2beta1之中。
另外,自Kubernetes 1.6版本起还为HPA增加了基于多个指标的扩展支持,用户可以使用autoscaling/v2beta1API版本为HPA配置多个指标以控制规模伸缩。运行时,HPA控制器将评估每个指标,并基于每个指标分别计算出各自控制下的新的Pod规模数量,结果值最大的即为采用的新规模标准。
1.4.2 HPA(v1)控制器
HPA也是标准的Kubernetes API资源,其基于资源配置清单的管理方式同其他资源相同。另外,它还有一个特别的“kubectl autoscale”命令用于快速创建HPA控制器。例如,首先创建一个名为myapp的Deployment控制器,而后通过一个同名的HPA控制器自动管控其Pod副本规模:
~]$ kubectl run myapp --image=ikubernetes/myapp:v1 --replicas=2 \ --requests='cpu=50m,memory=256Mi' --limits='cpu=50m,memory=256Mi' \ --labels='app=myapp' --expose --port=80 ~]$ kubectl autoscale deploy myapp --min=2 --max=5 --cpu-percent=60
通过命令创建的HPA对象隶属于“autoscaling/v1”群组,因此,它仅支持基于CPU利用率的弹性伸缩机制,可从Heapster或Metrics Service获得相关的指标数据。下面的命令用于显示HPA控制器的当前状态:
~]$ kubectl get hpa myapp -o yaml apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: …… spec: maxReplicas: 5 minReplicas: 2 scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: myapp targetCPUUtilizationPercentage: 60 status: currentCPUUtilizationPercentage: 0 currentReplicas: 2 desiredReplicas: 2
HPA控制器会试图让Pod对象相应资源的占用率无限接近设定的目标值。例如,向myapp-svc的NodePort发起持续性的压力测试式访问请求,各Pod对象的CPU利用率将持续上升,直到超过目标利用率边界的60%,而后触发增加Pod对象副本数量。待其资源占用率下降到必须要降低Pod对象的数量以使得资源占用率靠近目标设定值时,即触发Pod副本的终止操作,如图14-13所示。
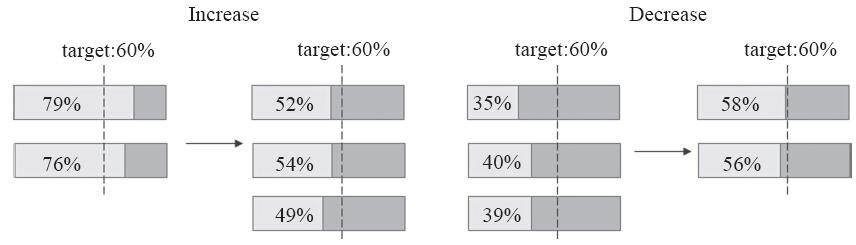
图14-13 HPA监控指标计算
下面是HPA控制器myapp在其详细信息“Events”中的一段内容,它显示了因资源占用率过高而增加Pod副本数量,以及资源占用率较低而降低Pod副本数量的部分操作事件:
Events: Type Reason Age From Message ---- ------ ---- ---- ------ Normal SuccessfulRescale 39m (x3 over 1h) horizontal-pod-autoscaler New size: 5; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 8m (x2 over 42m) horizontal-pod-autoscaler New size: 4; reason: All metrics below target Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 2; reason: All metrics below target
当然,用户可以通过资源配置清单定义HPA(v1)控制器资源,其spec字段嵌套使用的属性字段主要包含maxReplicas、minReplicas、scaleTargetRef和targetCPUUtilization-Percentage几个,其使用方式请参考相应的文档获取。尽管CPU资源利用率可以作为规模伸缩的评估标准,但大多数时候,Pod对象所面临的访问压力未必会直接反映到CPU之上。
1.4.3 HPA(v2)控制器
HPA(v2)控制器支持基于核心指标CPU和内存资源以及基于任意自定义指标资源占用状态实现应用规模的自动弹性伸缩,它从metrics-server中请求查看核心指标,从k8s-prometheus-adapter一类的自定义API中获取自定义指标数据,如图14-14所示。
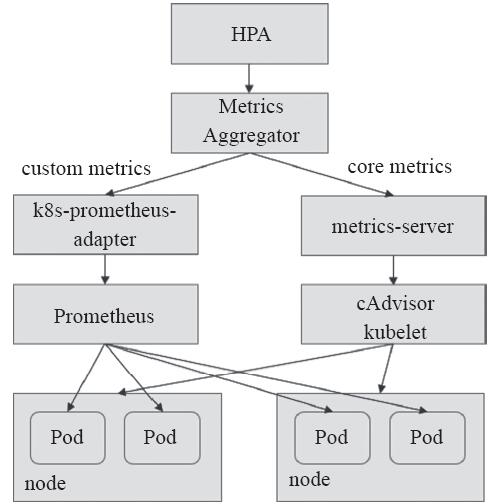
图14-14 HPA(v2)的数据指标获取方式
下面是一个HPA(v2)控制器的资源配置清单示例(hpa-v2-resources.yaml),它使用资源指标API获取两个指标CPU和内存资源的使用状况,并与其各自的设定目标进行比较,计算得出所需要的副本数量,两个指标计算的结果中数值较大的胜出:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: myapp spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: myapp minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 50 - type: Resource resource: name: memory targetAverageValue: 50Mi
将配置清单中的资源创建于集群中即可进行应用规模伸缩测试,其测试方式与1.4.2节中的过程相似,这里不再给出其具体的过程。细心的读者或许已经注意到,HPA(v2)尚且处于beta阶段,将来它有可能会发生部分改变,但目前的特性足以支撑起其核心功能。HPA(v2)控制器的创建语法遵循标准的API资源格式,由apiVersion、kind、metadata和spec字段组成,其中spec字段主要嵌套使用如下几个字段。
·minReplicas
·maxReplicas
·scaleTargetRef“object”:要缩放的目标资源,以及应该收集指标数据并更改其副本数量的Pod对象,引用目标对象时,主要会用到三个嵌套属性—apiVersion、kind和name。
·metrics<[]object>:用于计算所需Pod副本数量的指标列表,每个指标单独计算其所需的副本数,将所有指标计算结果中的最大值作为最终采用的副本数量。计算时,以资源占用率为例,所有现有Pod对象的资源占用率之和除以目标占用率所得的结果即为目标Pod副本数,因此增加Pod副本数量必然地会降低各Pod对象的资源占用率。
metrics字段值是对象列表,它由要引用的各指标的数据源及其类型构成的对象组成。
·external:用于引用非附属于任何对象的全局指标,甚至可以基于集群之外的组件的指标数据,如消息队列的长度等。
·object:引用描述集群中某单一对象的特定指标,如Ingress对象上的hits-per-second等。定义时,嵌套使用metricName、target和targetValue分别用于指定引用的指标名称、目标对象及指标的目标值。
·pods:引用当前被弹性伸缩的Pod对象的特定指标,如transactions-processed-per-second等,各Pod对象的指标数据取平均值后与目标值进行比较。定义时,嵌套使用metricName和targetAverageValue分别指定引用的指标名称和目标平均值。
·resource:引用资源指标,即当前被弹性伸缩的Pod对象中容器的requests和limits中定义的指标(CPU或内存资源)。定义时,嵌套使用name、targetAverageUtilization和targetAverageValue分别用于指定资源的名称、目标平均利用率和目标平均值。
·type:表示指标源的类型,其值可为Objects、Pods或Resource。
基于自定义指标API中的指标配置HPA对象时,其指标的来源途径还包括pods、object和external等,这其中又以Pod或引用的特定object的指标调用居多。下面通过一个示例来说明其用法,并测试其扩缩容的效果。
镜像文件ikubernetes/metrics-app在运行时会启动一个简单的Web服务器,它通过/metrics路径输出了http_requests_total和http_requests_per_second两个指标。下面是使用此镜像文件创建的Deployment控制器资源配置清单示例(metrics-app.yaml),它与此前正常使用的Deployment资源定义并无二致,除了特别附加的注解信息,包括其中的“prometheus.io/scrape:"true"”是使Pod对象能够被Prometheus采集相关指标的关键配置:
apiVersion: apps/v1 kind: Deployment metadata: labels: app: metrics-app name: metrics-app spec: replicas: 2 selector: matchLabels: app: metrics-app template: metadata: labels: app: metrics-app annotations: prometheus.io/scrape: "true" prometheus.io/port: "80" prometheus.io/path: "/metrics" spec: containers: - image: ikubernetes/metrics-app name: metrics-app ports: - name: web containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: metrics-app labels: app: metrics-app spec: ports: - name: web port: 80 targetPort: 80 selector: app: metrics-app
创建资源于集群中,启动一个专用的测试客户端Pod,在命令行中向创建出的Service端点的/metrics发起访问请求即可看到它输出的Prometheus兼容格式的指标及数据:
~]$ kubectl run client -it --image=cirros --rm -- /bin/sh / # curl metrics-app/metrics # HELP http_requests_total The amount of requests in total # TYPE http_requests_total counter http_requests_total 660 # HELP http_requests_per_second The amount of requests per second the latest ten seconds # TYPE http_requests_per_second gauge http_requests_per_second 0.5 / #
命令结果中返回了所有的指标及其数据,每个指标还附带了通过注释行提供的帮助(HELP)信息和类型(TYPE)说明。Prometheus通过服务发现机制发现新创建的Pod对象,根据注解提供的配置信息或默认配置识别各个指标并纳入采集对象,而后由k8s-prometheus-adapter将这些指标注册到Kubernetes的自定义指标API中,提供给HPA(v2)控制器和Kubernetes调度器等作为调度评估参数使用。当然,用户也可以直接向自定义指标API接口发起请求。
下面的资源配置清单示例(metrics-app-hpa.yaml)用于自动弹性伸缩前面基于metrics-app.yaml创建的metrics-app相关的Pod对象副本数量,其伸缩标准是接入HTTP请求报文的速率,具体的数据则经由各现有相关Pod对象的http_requests指标的平均数据同目标速率800m(即0.8个/秒)的比较来进行判定:
kind: HorizontalPodAutoscaler apiVersion: autoscaling/v2beta1 metadata: name: metrics-app-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: metrics-app # autoscale between 2 and 10 replicas minReplicas: 2 maxReplicas: 10 metrics: # use a "Pods" metric, which takes the average of the # given metric across all pods controlled by the autoscaling target - type: Pods pods: # use the metric that you used above: pods/http_requests metricName: http_requests # target 500 milli-requests per second, # which is 1 request every two seconds targetAverageValue: 800m
创建资源于集群中,而后启动一个测试客户端发起持续性测试请求,模拟压力访问以便其指标数据能够满足扩展规模之需:
~]$ kubectl run client -it --image=cirros --rm -- /bin/sh / # while true; do curl http://metrics-app; let i++; sleep 0.$RANDOM; done
持续测试十几分钟,结束后再等上一段时间,待平均请求速率降下来之后即可通过HPA控制器的详细信息了解其规模变动状况,然后将会得到类似如下规模变动的相关信息:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 18m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target Normal SuccessfulRescale 14m horizontal-pod-autoscaler New size: 5; reason: pods metric http_requests above target Normal SuccessfulRescale 11m horizontal-pod-autoscaler New size: 6; reason: pods metric http_requests above target Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 5; reason: All metrics below target Normal SuccessfulRescale 2s horizontal-pod-autoscaler New size: 4; reason: All metrics below target
借助自定义指标自动弹性伸缩应用规模的机制,赋予了不同应用程序根据核心指标控制自身规模的能力,这是Kubernetes系统除敏捷部署(Deployment等控制器)功能之外又一极具特色的特性,其使得应用运维人员从繁重的日常监控和运维工作中解脱出来。
1.5 小结
本篇介绍过第一代指标API及其实现方案Heapster之后,重点介绍了第二代监控架构体系、资源指标API、自定义指标API及其各自的解决方案,并对HPA及HPA(v2)的使用给予了详细说明。
·指标API是HPA控制器、Dashboard和调度器依赖的基础组件,它们分别在指标数据的基础上实现了应用规模的弹性伸缩、指标数据的展示和Pod对象的调度。
·Heapster是第一代的指标API实现方案,也是Kubernetes系统曾经必不可少的核心附加组件之一。
·新一代监控系统将指标划分为核心指标和自定义指标,并把API的定义同其实现分离开来。资源指标API的标准实现是Metrics Server,而自定义指标API的流行实现是Promethues及相应的适配器,如k8s-prometheus-adapter。
·HPA控制器第一代仅支持CPU指标数据,而第二代的HPA可基于各种核心指标和自定义指标实现应用规模的自动变动。
版权声明:如无特殊说明,文章均为本站原创,版权所有,转载需注明本文链接
本文链接:http://www.bianchengvip.com/article/Kubernetes-Resource-Metrics-and-HPA-Controller/