大家好,我是腾意。
Kubernetes系统的扩展和增强既包括扩展API Server所支持的资源类型及相关声明式功能的实现,以及消除集群的单点以实现集群的高可用等,也包括如何将系统增强为一个完整意义上的PaaS平台,并以DevOps文化为驱动改善工作流程等。
1.1 自定义资源类型(CRD)
Kubernetes API默认提供的众多的功能性资源类型可用于容器编排以解决多数场景中的编排需求。然而,有些场景也许要借助于额外的或更高级别的编排抽象,例如引入集群外部的一些服务并以资源对象的形式进行管理,再或者把Kubernetes的多个标准资源对象合并为一个单一的更高级别的资源抽象,等等。而这类API扩展抽象通常也应该兼容Kubernetes系统的基本特性,如支持kubectl管理工具、CRUD及watch机制、标签、etcd存储、认证、授权、RBAC及审计,等等,从而使得用户可将精力集中于构建业务逻辑本身。
目前,扩展Kubernetes API的常用方式有三种:使用CRD(CustomResourceDefinitions)自定义资源类型、开发自定义的API Server并聚合至主API Server,以及定制扩展Kubernetes源码。其中,CRD最为易用但限制颇多,自定义API Server更富于弹性但代码工作量偏大,而仅在必须添加新的核心类型才能确保专用的Kubernetes集群功能正常时才应该定制系统源码。
在某种程度上,Kubernetes API Server可以看作一个JSON方案的数据库存储系统,它内建了众多数据模式(资源类型),以etcd为存储后端,支持存储和检索结合内建模式进行实例化的数据项(对象)。作为客户端,控制器会收到有关这些资源对象变动的通知,并在响应过程中操纵这些对象及相关的其他资源,或者将这些更改反映到外部系统(如云端的软件负载平衡器)。从这个角度进行类比,CRD就像是由用户为Kubernetes存储系统提供的自定义数据模式,基于这些模式进行实例化的数据项一样可以存入系统中。
CRD并非设计用来取代Kubernetes的原生资源类型,而是用于补充一种简单易用的更为灵活和更高级别的自定义API资源的方式。虽然目前在功能上仍存在不少的局限,但对于大多数的需求场景来说,CRD的表现已经足够好,因此在满足需求的前提下是首选的API资源类型扩展方案。
1.1.1 创建CRD对象
CRD自Kubernetes 1.7版开始引入,并自1.8版起完全取代其前身TPR(ThirdParty-Resources),其设计目标是无须修改Kubernetes源代码就能扩展它支持使用API资源类型。CRD本身也是一种资源类型,隶属于集群级别,实例化出特定的对象之后,它会在API上注册生成GVR类型URL端点,并能够作为一种资源类型被使用并实例化相应的对象。自定义资源类型之前,选定其使用的API群组名称、版本及新建的资源类型名称,根据这些信息即可创建自定义资源类型,并创建自定义类型的资源对象,其流程如图13-1所示。

图13-1 创建自定义资源类型及自定义类型的资源对象
下面的配置清单中定义了一个名为users.auth.ilinux.io的CRD资源对象,它的群组名称为auth.ilinux.io,仅支持一个版本级别v1beta1,复数形式为users,隶属于名称空间级别,因此,它的对象在API上的URL路径前缀为/apis/auth.ilinux.io/v1beta1/namespace/NS_NAME/users/:
apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: users.auth.ilinux.io spec: group: auth.ilinux.io version: v1beta1 names: kind: User plural: users singular: user shortNames: - u scope: Namespaced
配置清单中,spec嵌套使用的字段都能够见名知义,这里需要特别说明的是,metadata.name字段的值必须等同于spec字段中的“
~]$ kubectl get crd NAME CREATED AT users.auth.ilinux.io 2018-08-24T12:51:54Z
现在,在API群组auth.ilinux.io/v1beta1中,users已经是一个名称空间级别的可用资源类型,用户可按需创建出任意数量的users类型的对象,下面就是一个资源清单示例,它定义了一个名为admin的users对象:
apiVersion: auth.ilinux.io/v1beta1 kind: User metadata: name: admin namespace: default spec: userID: 1 email: k8s@ilinux.io groups: - superusers - adminstrators password: ikubernetes
自定义资源类型users并未限制其spec字段中可嵌套使用的字段及其数据类型,于是用户可按需随意使用任何字段名及字段值,例如上面的资源清单中使用的userID、email和groups等字段。资源创建完成后即可使用users作为类型标识使用kubectl命令完成资源对象的管理,包括查看、删除、修改等操作。例如,将清单中的自定义资源创建于名称空间中,而后使用类似如下的命令获取相关的状态信息:
~]$ kubectl get users -n default NAME AGE admin 10s
根据API对象GVR格式的URL规范,users资源的对象admin的引用路径为/apis/auth.ilinux.io/v1beta1/namespaces/default/users/admin,这一点可以通过describe命令予以证实。而要删除自定义的users对象admin,只要使用通用格式的kubectl命令即可,如“kubectl delete users admin”,或者使用陈述式对象配置命令“kubectl delete-f
1.1.2 自定义资源格式验证
除了对操作请求进行身份认证和授权检查之外,对象配置的变动在存入etcd之前还需要经由准入控制器的核验,尤其是验证型(validation)控制器会检查传入的对象格式是否符合有效格式,包括是否设定了不符合定义的数据类型值,以及是否违反了字段的限制规则等。
Kubernetes自1.9版本起支持为CRD定义验证(validation字段)机制用以定义CRD可用的有效字段等,这在将设计的自定义资源公开应用时非常重要。自定义资源可使用OpenAPI模式声明验证规则,该模式是JSON模式的子集。需要注意的是,OpenAPI架构并不能支持JSON架构的所有功能,而CRD验证也不能支持OpenAPI架构的所有功能,不过,对于大多数情况来说,它足够用了。
提示 CRD的validation中支持使用的限制机制、数据类型及数据格式等请参考其API手册。
下面是一个配置清单片段,将其合并添加到1.1.1节中CRD对象users.auth.ilinux.io配置清单的spec内即能生效。它分别定义了userID、groups、email和password字段的数据类型,并指定了userID字段的取值范围,以及password字段的数据格式,而且还通过required指定userID和groups是必选字段:
spec: validation: openAPIV3Schema: properties: spec: properties: userID: type: integer minimum: 1 maximum: 65535 groups: type: array email: type: string password: type: string format: password required: ["userID","groups"]
限制了每个字段的数据类型之后,验证机制会检查创建或修改操作中提供的每个字段值等是否违反了格式要求,任何的核验失败都会导致写入操作被拒绝。下面的内容是某次创建操作返回的错误提示,它显示命令提供的对象配置信息违反了userID字段的取值范围,并且缺少必选字段:spec.groups。
The User "tony" is invalid: []: … …: validation failure list: spec.userID in body should be less than or equal to 65535 spec.groups in body is required
自Kubernetes 1.11版本开始,kubectl即使用服务器侧对象信息打印机制,这意味着将由API Server决定kubectl get命令结果会显示哪些字段。在CRD资源中,可在spec.additionalPrinterColumns中嵌套定义在对象的详细信息中要打印的字段列表。下面的配置清单片断定义了要为users类型的对象显示相关的四个字段,将其合并至前面定义的CRD对象users配置清单的spec字段中,重新应用到集群中并确保其正常生效:
spec: additionalPrinterColumns: - name: userID type: integer description: The user ID. JSONPath: .spec.userID - name: groups type: string description: The groups of the user. JSONPath: .spec.groups - name: email type: string description: The email address of the user. JSONPath: .spec.email - name: password type: string description: The password of the user account. JSONPath: .spec.password
以上四个字段会显示在get、describe等命令查看users类型的对象状态信息的输出结果中:
~]$ kubectl get users admin NAME USERID GROUPS EMAIL PASSWORD admin 1 [superusers administrators] k8s@ilinux.io ikubernetes
当然,在对象中以明文字符串保存密码并不是一个好的选择,真正用到时,应该使用Secret对象保存密钥信息,并在users对象中进行引用。
1.1.3 子资源
可能有读者已经注意到,前面自定义资源users的对象admin在其详细状态信息输出中没有类似核心资源的status字段,该字段是一种用于保存对象当前状态的子资源。在Kubernetes系统的声明式API中,status字段至关重要,它由Kubernetes系统自行维护,相关的控制器在和解循环中持续与API Server进行通信,并负责确保status字段中的状态匹配spec字段中定义的期望状态。
在Kubernetes 1.10版本之前,自定义资源的API端点不区分spec和status字段,而自1.10版本起,自定义资源开始支持通过/status子资源的方式提供对象的当前状态,虽然它仍然不会显示于获取状态信息的命令结果输出中,但客户端可通过对象的子URL路径来获取状态信息。此特性在1.11版本中已经升级至beta级别。
在CRD中为自定义资源启用status字段的方式非常简单,只需要为其定义spec.subresources.status字段即可,其内嵌的字段等由系统自行维护,用户无须提供任何额外的配置。它的使用格式如下:
spec: subresources: status: {}
将上面配置清单中的配置片段合并至前面创建的CRD对象users的配置中,并完成活动对象的修改即可在其实例化出的对象上通过/status获取状态信息,如对象admin的状态引用路径为/apis/auth.ilinux.io/v1beta1/namespaces/default/users/admin/status。不过,在没有相应资源控制器的情形下,活动对象状态的非计划内变动既不会实时反映到status中,也不会向spec定义的期望状态转换。
事实上,如果有相应的资源控制器维护自定义的资源类型时,还可以在配置自定义资源对象时使用scale子资源和status子资源协同实现类似Deployment或StatefulSet等控制器一样对象规模的伸缩功能。它的定义格式如下:
spec: status: {} scale: specReplicasPath: statusReplicasPath: labelSelectorPath:
需要注意的是,scale字段必须与status字段一起使用,由控制器通过status获取对象当前的副本数量,并与spec字段内嵌套的用于指定副本数量的字段(例如,常用的replicas)进行比较来确定其所需要执行的伸缩操作,而后再将伸缩操作的结果更新至status字段中。上面的配置格式中,scale的各内嵌字段功用说明具体如下。
·specReplicasPath
·statusReplicasPath
·labelSelectorPath
为某CRD资源定义scale子资源之后,即可实例化出支持规模伸缩的自定义资源对象。但必须存在一个相应的资源控制器来持续维护相应的自定义资源对象,以确保其当前状态匹配期望的状态。满足条件后,类似于Deployment资源对象等,使用“kubectl scale”命令就能完成对自定义资源对象规模的手动伸缩。
1.1.4 使用资源类别
类别(categories)是Kubernetes 1.10版本引入的一种分组组织自定义资源的方法,定义CRD对象时为其指定一个或多个类别,可以通过kubectl get
spec: names: categories: - all
categories字段的值是自定义资源所属的分组资源列表。而后,创建的所有自定义类型users的对象都能够通过“kubectl get all”命令进行获取:
~]$ kubectl get all …… NAME USERID GROUPS EMAIL user.auth.ilinux.io/admin 1 [superusers administrators] k8s@ilinux.io
1.1.5 多版本支持
Kubernetes原生资源的一个引人注目的特性是它们能够在API版本之间自动和透明地迁移。资源的使用者可以使用混合API版本,并且都能获得他们所期望的资源版本。而自Kubernetes 1.11版本开始,CRD支持多个版本,但它们之间的转换必须手动完成。
在CRD上使用多版本机制时,将spec.version字段替换为spec.versions字段,并将支持的各版本以对象列表的形式给出定义即可。不过,多版本并存时,仅其中一个版本且必须有一个版本应标记为存储(spec.versions[].storage字段)版本。下面的配置清单片断中定义了两个API版本,其中仅v1beta1标记为了storage:
spec: versions: - name: v1beta1 served: true storage: true - name: v1beta2 served: true storage: false
将上述配置清单版本并入此前定义的users资源配置清单中并应用于活动对象后再创建相应类型的自定义对象时就可以通过两个不同的API版本之一来完成。
1.1.6 自定义控制器基础
仅借助于CRD完成资源自定义本身并不能为用户带来太多的价值,它只是资源类型的定义,只是提供了JSON格式的数据范式及存取相关数据的能力,至于如何执行数据相关的业务逻辑,时刻确保将status中的状态移向spec中的状态则是由封装于控制器中的代码来负责实现的。相应地,为自定义资源类型提供业务逻辑代码的控制器需要由用户自行开发,并运行为API Server的客户端程序(通常是托管运行于Kubernetes系统之上,类似于Ingress控制器),这就是所谓的自定义控制器(Custom Controller)。换句话讲,某特定的CRD资源的相关对象发生变动时,如何确保它的当前状态不断地接近期望的状态并非API Server的功能,而是相关的专用控制器组件。
事实上,自定义控制器不仅仅能够用于管理CRD资源,用户也完全可以仅针对系统内建的核心类型对象开发更高级别的控制器,这些对象类型包括Service、Deployment、ConfigMap等。不过,对于每个CRD的自定义类型来说,至少应该存在一个相关的自定义控制器,如图13-2所示。
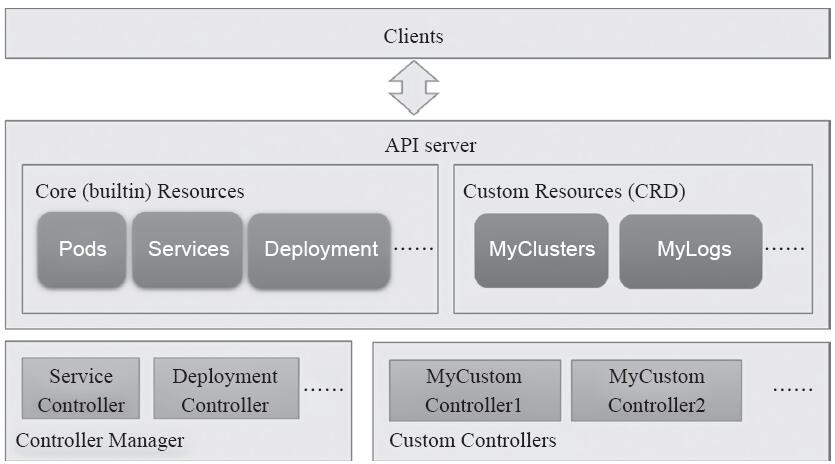
图13-2 Kubernetes核心资源与CRD
简单来说,控制器负责持续监视资源变动,根据资源的spec及status中的信息执行某些操作逻辑,并将执行结果更新至资源的status中。自定义控制器同样担负着类似的职责,只不过一个特定的控制器通常仅负责管理一部分特定的资源类型,并执行专有管理逻辑。
Kubernetes系统内建了许多控制器,如NodeController、ServiceController等,它们打包在一起并作为一个统一守护进程kube-controller-manager。这些控制器基本上都遵循同一种模式以完成资源管理操作,该模式通常可描述为三种特性:声明式API、异步和水平式处理。
·声明式API:用户定义期望的状态而非要执行的特定操作,如使用kubectl apply命令将请求发送至API Server存储于etcd中,并由API Server做出处理响应。
·异步:客户端的请求于API Server存储完成之后即返回成功信息,而无须等待控制器执行的和解循环结束。
·水平式处理(level-based):同一对象有多次变动事件待处理时,控制器仅需要处理其最新一次的变动。这种根据最新观察结果而非历史变化来和解status和spec的机制即为水平式处理机制。
自定义控制器实现自定义资源管理行为的最佳方法同样是遵循此类控制器模式进行程序开发,目前,大部分开发接口都是基于Golang语言来实现的,相关代码位于客户端库的client-go/go/tools/cache和client-go/util/workqueue目录中。
简单来说,控制器包含两个重要组件:Informer/SharedInformer和Workqueue,前者负责监视资源对象当前状态的更改,并将事件发送至后者,而后由处理函数进行处理,如图13-3所示。
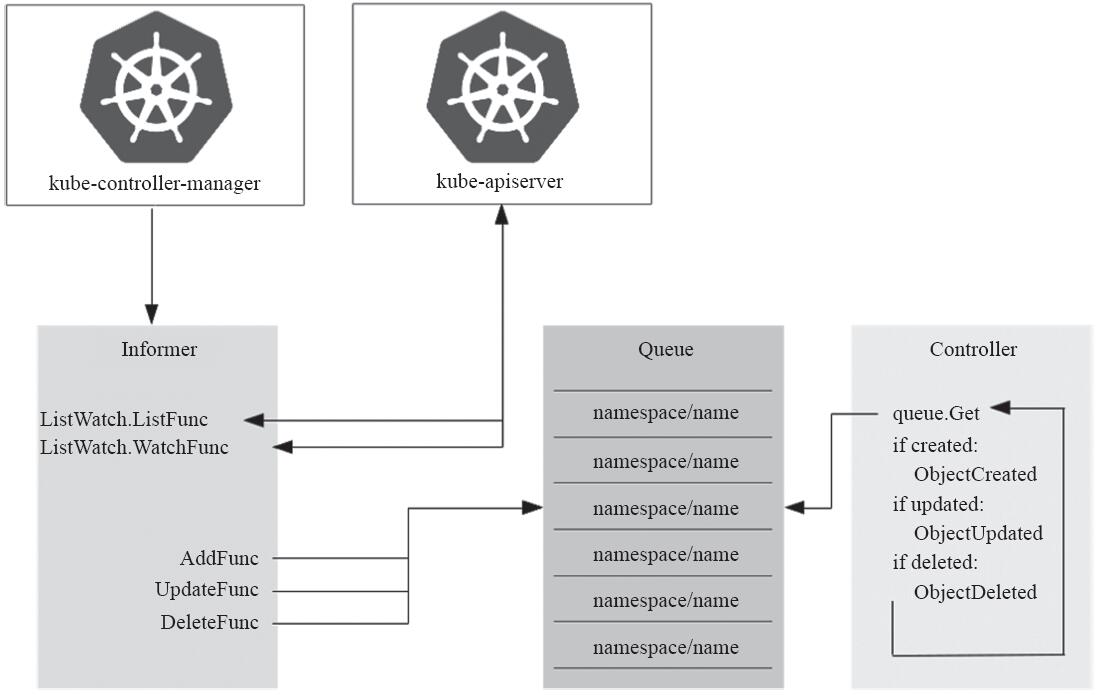
图13-3 处理器事件流动示意图(图片来源:https://medium.com/@trstringer )
Informer主要由Listwatcher、ResourceEventHandler和ResyncPeriod三类函数组件进行构造。
·Listwatcher是应用于特定名称空间中特定资源对象的列表函数(listFunc)和监视函数(watchFunc),并结合字段选择器为控制器精确限定关注的资源对象。
·ResourceEventHandler负责处理资源对象状态改变产生的相关通知,其分别使用AddFunc、UpdateFunc和DeleteFunc三个函数完成对象的创建、更新和删除操作。
·ResyncPeriod定义控制器遍历缓存中的所有项目并触发运行UpdateFunc的频率,即和解循环的执行频度。较高的频度对于控制器错过某次更新或此前的更新操作执行失败时非常有用,但会对系统资源带来较高的压力,因此具体的时长需要全面、系统地进行权衡。
Informer是控制器的私有组件,它为相关资源对象创建的缓存信息仅可供当前控制器使用。而在Kubernetes系统上,同一资源对象支持多个控制器共同处理,而且多个控制器监视同一资源对象也是较为常见的情形,于是,一个更高效的方式是使用替代解决方案SharedInformer和Workqueue。SharedInformer支持在监控同类资源对象的控制器之间创建共享缓存,这有效降低了内存资源开销,而且它也仅需要在上游的API Server中注册创建一个监视器,即能显著减轻上游服务器的访问压力。因此,较之Informer,SharedInformer才是更为常用的解决方案。
不过,SharedInformer无法跟踪每个控制器的位置(因为它是共享的),于是控制器必须负责提供自用的工作队列及重试机制,这也意味着它的ResourceEventHandler程序只是将事件放在每个消费者的Workqueue中。
·每当资源发生变化时,ResourceEventHandler程序都会将一个键放入工作队列中,对于名称空间级别资源对象的相关事件,其键名格式为
·目前,工作队列存在延迟队列、定时队列和速率限制队列等几种形式。
因此,自定义控制器构建起来存在一定的复杂度。实践中,为了便于用户使用client-go创建控制器,Kubernetes社区发布了模板类的项目workqueue example和sample-controller,它们提供了一个自定义控制器项目应有的基础结构。通常的做法是复制相应的代码并按需修改相应的部分,例如,将syncHandler修改为自定义资源类型业务处理逻辑等,而后借助于code-generator项目用脚本完成相应的组件,如typed clients、informers等。虽然好过从零构建自定义控制器的代码,但这类方式总觉得有些不趁手和美中不足。
好在,现在已经有了几类更加成熟、更易上手的工具可用,它们甚至已经可以被视作开发CRD和控制器的SDK或框架,其中,主流的项目主要有Kubebuilder、Operator SDK和Metacontroller三个。Kubebuilder主要由Google的工程师Phillip Wittrock创立,但目前归属于SIG API Machinery,有较完善的在线文档。Operator SDK是CoreOS发布的开源项目,是Operator Framework的一个子集,其出现时间略早,社区接受度较高,以致很多人干脆就把自定义控制器与Operator当作同一事物不加区分地使用,目前已经有etcd、Prometheus、Rook和Vault几个成熟的Operator可用。Metacontroller由GCP发布,与前两者的区别较大,它将控制器模式直接委托给Metacontroller框架,并调用用户提供的WebHook实现模式的处理功能,支持任何编程语言开发,接收并返回JSON格式的序列化数据。
1.2 自定义API Server
扩展Kubernetes系统API接口的另一种常用办法是使用自定义的API Server。相较于CRD来说,使用自定义API Server更加灵活,例如可以自定义资源类型和子资源、自定义验证及其他逻辑,甚至于在Kubernetes API Server中实现的任何功能也都能在自定义API Server中实现。
1.2.1 自定义API Server概述
自定义API Server完全可以独立运行并能够被客户端直接访问,但最方便的方式是将它们与主API Server(kube-apiserver)聚合在一起使用,这样不仅可以使得集群中的多个API Server看起来好像是由单个服务器提供服务,集群组件和kubectl等客户端可不经修改地继续正常通信,而且也无须特殊逻辑来发现不同的API Server等操作。在kube-apiserver中,用于聚合自定义API Server的组件是kube-aggregator,它自Kubernetes 1.7版本引入,并内建于主API Server之中作为其进程的一部分来运行,如图13-4所示。
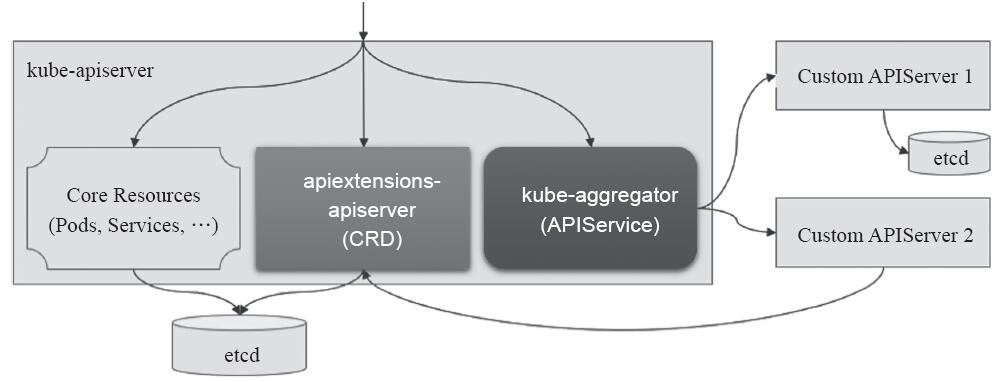
图13-4 自定义API服务器及APIService资源
在使用自定义API Server中的扩展资源之前,管理员需要在主API Server上添加一个相应的APIService资源对象,将自定义API Server注册到kube-aggregator之上,以完成聚合操作。一个特定的APIService对象可用于在主API Server上注册一个URL路径,如/apis/auth.ilinux.io/v1beta1/,从而使得kube-aggregator将发往这个路径的请求代理至相应的自定义API Server。每个APIService对应于一个API群组版本,不同版本的单个API可以由不同的APIService对象支持,如图13-5所示。
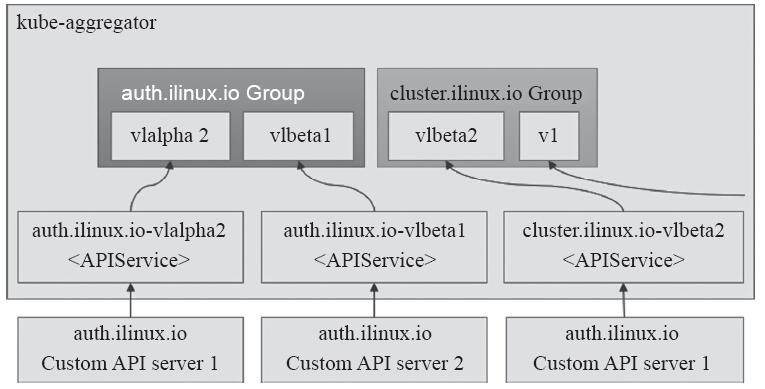
图13-5 Kubernetes聚合层及其聚合方式
相对于CRD和自定义控制器来说,开发自定义API Server要复杂得多,Kubernetes为此也提供了专用的构建聚合API Server的通用库,项目名称就叫作apiserver。apiserver开发库包含了用于创建Kubernetes聚合服务器的基础代码,其中包含委派的authentication和authorization,以及kubectl兼容的发现机制、可选的许可控制链(admission chain)和版本化类型(versioned type)等,同时,它还有一个示例性的项目的sample-apiserver可用作开发模板。不过,目前最好的实践方式是借助于专用于构建聚合服务器的项目apiserver-builder进行开发,它提供了基于apiserver代码构建原生Kubernetes扩展资源的开发库和开发工具的集合。
但创建自定义API Server需要编写大量的代码,而且每个自定义的API Server都需要自行管理所使用的存储系统,它们可使用自有的etcd存储服务,也可通过CRD将资源数据存储于主API Server的存储系统中,但此场景需要事先创建依赖到的所有自定义资源。除非特别需要创建自定义的API Server,否则还是建议读者选择使用Kubebuilder直接基于CRD和自定义控制器进行系统扩展。
1.2.2 APIService对象
APIService资源类型的最初设计目标是用于将庞大的主API Server分解成多个小型但彼此独立的API Server,但它也支持将任何遵循Kubernetes API设计规范的自定义API Server聚合进主API Server中。
下面的配置清单示例取自sample-apiserver项目,它定义了一个名为v2beta1.auth.ilinux.io的APIService对象,用于将default名称空间中名为auth-api的Service对象后端的自定义API Server聚合进主API Server中:
apiVersion: apiregistration.k8s.io/v1beta1 kind: APIService metadata: name: v2beta1.auth.ilinux.io spec: insecureSkipTLSVerify: true group: auth.ilinux.io groupPriorityMinimum: 1000 versionPriority: 15 service: name: auth-api namespace: default version: v2beta1
定义一个APIService对象时,其Spec嵌套使用的字段包括如下这些字段。
·group
·groupPriorityMinimum
·version
·versionPriority
·service"Object":自定义API Server相关的Service对象,是真正提供API服务的后端,它必须通过443端口进行通信。
·caBundle
·insecureSkipTLSVerify
APIService仅用于将API Server进行聚合,真正提供服务的是相应的外部API Server,这个自定义服务器通常应该以Pod的形式托管运行于当前Kubernetes集群之上。于是,在Kubernetes集群上部署使用自定义API Server主要由两步组成,首先需要将自定义API Server以Pod形式运行于集群之上并为其创建Service对象,而后创建一个专用的APIService对象与主API Server完成聚合。Kubernetes系统的系统资源指标API就由metrics-server项目提供,该项目基于metrics-server提供了一个扩展的API,并通过API群组metrics.k8s.io将其完成聚合,后文中资源指标及监控相关的章节将讲述相关的部署及使用方法。
1.3 Kubernetes集群高可用
Kubernetes具有自愈能力,当它跟踪到某工作节点发生故障时,控制平面可以将离线节点上的Pod对象重新编排至其他可用的工作节点上运行,因此,更多的工作节点也就意味着更好的容错能力,因为它使得Kubernetes在实现工作节点故障转移时拥有更加灵活的自由度。而当管理员检测到集群负载过重或无法容纳其更多的Pod对象时,通常需要手动将节点添加到集群,其过程略为烦琐,Kubernetes cluster-autoscaler还为集群提供了规模按需自动缩放的能力。
然而,添加更多的工作节点并不能使集群适应各种故障,例如,若主API服务器出现故障(由于其主机出现故障或网络分区将其从集群中隔离),则其将无法再跟踪和控制集群。因此,还需要冗余控制平面的各组件以实现主节点的服务高可用性。基于冗余数量的不同,控制平面能容忍一个甚至是多个节点的故障。一般来说,高可用控制平面至少需要三个Master节点来承受最多一个Master节点的丢失,才能保证等待状态的Master节点能够保持半数以上,以满足节点选举时的法定票数。一个最小化的Master节点高可用架构如图13-6所示。
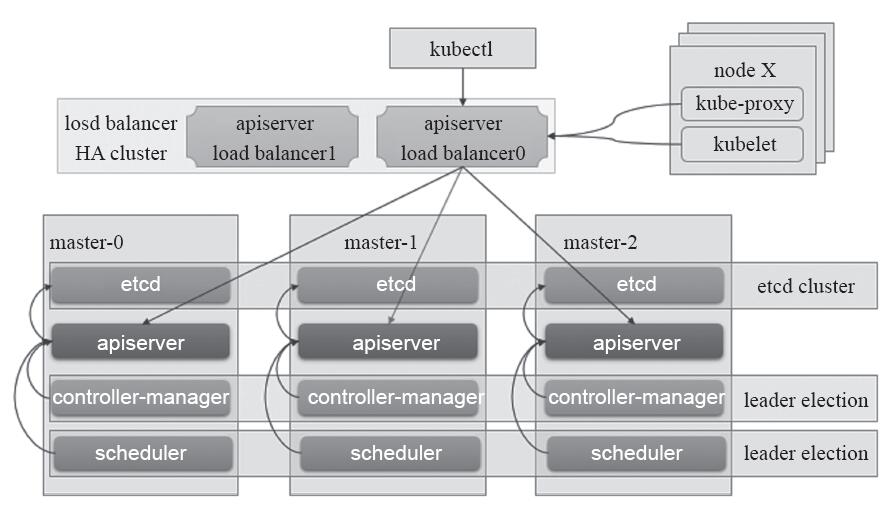
图13-6 最小化Master节点高可用架构
Kubernetes组件中仅etcd需要复杂逻辑完成集群功能,其他组件间的松耦合特性使得系统能够通过多种方式实现Master节点的高可用性,图13-6是较为常用的一种架构,各架构方式也通常有一些共同的指导方针,具体如下。
·利用etcd自身提供的分布式存储集群为Kubernetes构建一个可靠的存储层。
·将无状态的apiserver运行为多副本,并在其前端使用负载均衡器调度请求;需要注意的是,负载均衡器本身也需要是高可用的。
·多副本的控制器管理器,通过其自带的leader选举功能(--leader-election)选举出主角色,余下的副本在主角色发生故障时自动启动新一轮的选举操作。
·多副本的调度器,通过其自带的leader选举功能(--leader-election)选举出主角色,余下的副本在主角色发生故障时自动启动新一轮的选举操作。
1.3.1 etcd高可用
分布式服务之间进行可靠、高效协作的关键前提是有一个可信的数据存储和共享机制,etcd项目正是致力于此目的构建的分布式数据存储系统,它以键值格式组织数据,主要用于配置共享和服务发现,也支持实现分布式锁、集群监控和leader选举等功能。
etcd基于Go语言开发,内部采用raft协议作为共识算法进行分布式协作,将数据同步存储在多个独立的服务实例上以提高数据的可靠性,从而避免了单点故障所导致的数据丢失。Raft协议通过选举出的leader节点来实现数据的一致性,由leader节点负责所有的写入请求并同步给集群中的所有节点,在取决半数以上follower节点的确认后予以持久存储。这种需要半数以上节点投票的机制要求集群数量最好是奇数个节点,推荐的数量为3个、5个或7个。etcd集群的建立有三种方式,具体如下。
·静态集群:事先规划并提供所有节点的固定IP地址以组建集群,仅适合于能够为节点分配静态IP地址的网络环境,好处是它不依赖于任何外部服务。
·基于etcd发现服务构建集群:通过一个事先存在的etcd集群进行服务发现来组建新集群,支持集群的动态构建,它依赖于一个现存可用的etcd服务。
·基于DNS的服务资源记录构建集群:通过在DNS服务上的某域名下为每个节点创建一条SRV记录,而后基于此域名进行服务发现来动态组建新集群,它依赖于DNS服务及事先管理妥当的资源记录。
一般说来,对于etcd分布式存储集群来说,三节点集群可容错一个节点,五节点集群可容错两个节点,七节点集群可容错三个节点,依次类推,但通常来说,多于七个节点的集群规模是没有必要的,而且对系统性能也会产生负面影响。
1.3.2 Controller Manager和Scheduler高可用
Controller Manager通过监控API Server上的资源状态变动并按需分别执行相应的操作,于是,多实例运行的kube-controller-manager进程可能会导致同一操作行为被每一个实例分别执行一次,例如,某一Pod对象创建的请求被3个控制器实例分别执行一次进而创建出一个Pod对象副本来。因此,在某一时刻,仅能有一个kube-controller-manager实例处于正常工作状态,余下的均处于备用状态,或者称为等待状态。
多个kube-controller-manager实例要同时启用“--leader-elect=true”选项以自动实现leader选举,选举过程完成后,仅leader实例处于活动状态,余下的其他实例均转入等待模式,它们会在探测到leader故障时进行新一轮的选举。与etcd集群基于raft协议进行leader选举不同的是,kube-controller-manager集群各自的选举操作仅是通过在kube-system名称空间中创建一个与程序同名的Endpoints资源对象来实现:
~]$ kubectl get endpoints -n kube-system NAME ENDPOINTS AGE kube-controller-manager <none> 13h kube-scheduler <none> 13h …
这种leader选举操作是分布式锁机制的一种应用,它通过创建和维护Kubernetes资源对象来维护锁状态,目前Kubernetes支持ConfigMap和Endpoints两种类型的资源锁。初始状态时,各kube-controller-manager实例通过竞争的方式去抢占指定的Endpoints资源锁。胜利者将成为leader,它通过更新相应的Endpoints资源的注解control-plane.alpha.kubernetes.io/leader中的“holderIdentity”为其节点名称,从而将自己设置为锁的持有者,并基于周期性更新同一注解中的“renewTime”以声明自己对锁资源的持有状态从而避免等待状态的实例进行争抢。于是,一旦某leader不再更新renewTime了,等待状态的各实例就将一哄而上进行新一轮的竞争。
~]$ kubectl describe endpoints kube-controller-manager -n kube-system Name: kube-controller-manager Namespace: kube-system Labels: <none> Annotations: control-plane.alpha.kubernetes.io/leader={"holderIdentity":"master1. ilinux.io_846a3ce4-b0b2-11e8-9a23-00505628fa03","leaseDurationSeconds":15,"acquireTime": "2018-09-05T02:22:54Z","renewTime":"2018-09-05T02:40:55Z","leaderTransitions":1}' Subsets: Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal LeaderElection 13h kube-controller-manager master0.ilinux.io_e8fca6fc- b049-11e8-a247-000c29ab0f5b became leader Normal LeaderElection 5m kube-controller-manager master1.ilinux.io_846- a3ce4-b0b2-11e8-9a23-00505628fa03 became leader
kube-scheduler的实现方式与此类似,只不过它使用的是自己专用的Endpoints资源kube-scheduler。
提示 基于kubeadm部署高可用集群的方式可参考文档https://kubernetes.io/docs/setup/independent/high-availability/ 给出的步骤来进行。
1.4 Kubernetes的部署模式
Kubernetes在容器生态系统的快速增长过程中形成了多种部署模式,包括自助式、自托管式和完全自动化等多种管理形式的集群。无论部署方式如何,开发人员和运营团队都要遵循标准化、一致的工作流程来管理容器化应用程序的生命周期,这也恰是Kubernetes的关键优势之一。
实践中,Kubernetes的客户可以使用各种各样的部署模型,包括对开发人员友好的PaaS模型以及高度自定义的运行于裸服务器的部署模型,等等,其中的每种模式都有其优缺点。通常,将容器部署到本地服务器时,数据的持久存储是最大的挑战,而对于那些部署到云环境的模型来说,引用监视和日志记录则是其最大的挑战。另外,安全性是任何Kubernetes部署模型的核心因素,任何部署操作从设计时就应该充分考虑到其安全性。
本节主要描述Kubernetes系统较为常用的部署模型,以帮助读者理解其部署选项,与每个选项相关的挑战和考虑因素,以及在其中运行生产型工作负载的管理模型。
1.4.1 关键组件
生产可用的部署方案中,除了Kubernetes之外,还有多个对生产集群来说至关重要的组件,如镜像仓库、监控系统、日志系统等,如图13-7所示。
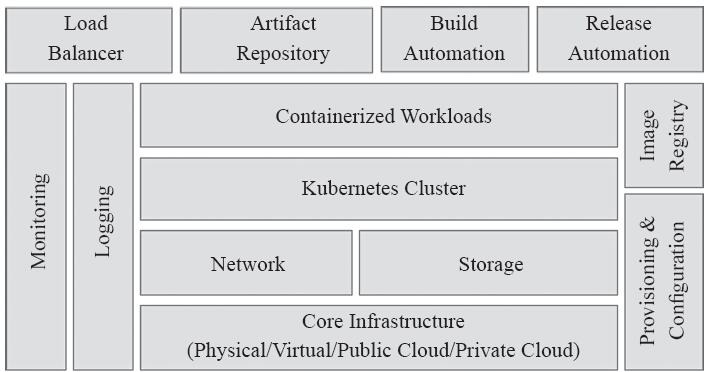
图13-7 Kubernetes集群的关键组件
1)核心基础架构:此为Kubernetes集群的基础设施组件,用于提供支持容器化工作负载的计算、网络及存储相关的底层部件,它们可能是物理服务器、虚拟化数据中心、IaaS类型的私有云或公有云。
2)叠加网络:Kubernetes基于SDN(Software-Defined Networking)提供的网络环境实现内部通信,它将用于确保集群的所有内部组件都能够正常通信,可以选用的项目包含诸如Calico、Flannel、Romana和Weave Net等,这在前面的章节中已经有过详细的讲解。
3)存储系统:运行有状态的工作负载(如数据库)时,持久化数据存储是必备的组件。SDS(Software-Defined Storage)层即作为持久存储卷暴露给容器,分布式存储软件如GlusterFS、网络文件系统(NFS)和块级别存储卷(RBD等)是首选。
4)Kubernetes集群:由控制平面Master节点、分布式键值存储系统etcd和工作节点组成。主节点负责工作负载的调度和编排,主要由API服务器、控制器管理器和调度器组成。它们是Kubernetes集群的控制中心,生产环境中需要冗余化配置以确保服务的可用性。etcd存储系统负责维护集群和工作负载的当前状态,鉴于其重要性通常需要为其配置分布式环境以实现冗余和高可用性。各工作节点负责运行工作负载,在云计算环境中此部分可由Cluster AutoScaler实现弹性伸缩。
5)容器化工作负载:于Kubernetes集群内部署的应用程序,其中一部分有可能需要暴露给集群外部的客户端程序。
6)供应和配置管理:安装和配置Kubernetes集群与部署高度可用的关键型分布式应用程序并无太大区别。为了确保一致性和可重复性,通常应该依赖于工具链的实现,类似Ansible、Chef、Puppet、Terraform和其他自动化工具。这些工具使得升级、修补和维护Kubernetes基础架构变得更加容易。
7)镜像仓库:运行容器化应用程序时,Kubernetes节点需要事先从镜像仓库中提取相应的容器镜像。在每次提交代码时自动构建新镜像的环境中,应用程序将自动升级为最新版本的镜像。为了减少延迟并提高安全性,镜像应该存储在托管于集群之上的仓库服务中。
8)日志记录和监控:分布式应用程序会生成大量日志,Kubernetes也不例外。集群中的每个组件(包括已部署的应用程序)都会生成需要捕获和处理的日志,它们对故障排查和监视群集活动有着不可替代的作用。日志与监控工具结合使用,有助于深入了解集群的运行状态,常用的实现有如Elastic Stack、Grafana和Prometheus等。该层是生产部署的重要组成部分。
9)负载均衡器:Kubernetes集群有两处位置依赖于负载均衡器,它们分别是API服务器和公共类型的容器化应用。配置了高可用服务的Master节点上,API服务器经负载均衡器调度以承载更多的用户请求,而提供公共服务的应用程序运行于多个Pod对象并向集群外部暴露时也需要负载均衡器。
10)工件仓库:工件仓库用于维护属于应用程序的资产,尤其是随着分布式应用程序复杂性的增长,需要管理的程序资产包括各种配置设定、依赖项、软件包、脚本,甚至是二进制文件。在某些情况下,工件仓库本身甚至也具有镜像仓库的功能。
11)构建和发布管理:随着持续集成和持续交付成为应用程序生命周期管理(ALM)的首选机制,构建和发布自动化正在成为IT组织核心文化,实现此类功能的自动化工具通过高效的流水线来连接源代码管理系统和生产环境。
1.4.2 常见的部署模式
Kubernetes是近来最为成功的开源项目之一,在CNCF的主导下,它得到了来自于CoreOS、Google、华为、IBM、RedHat和中兴通讯等公司程序员的积极贡献,源代码质量较高且经过了社区的严格评估,托管于GitHub之上的代码仓库中的主干代码可直接用于部署生产环境。不过,据CNCF于2017年秋季的调查显示,实施的复杂性仍是许多组织不使用Kubernetes的主要原因之一。
幸运的是,Kubernetes项目在日渐成熟的过程中,社区为系统的安装简化也正在倾力而为。尽管该软件的初始版本安装起来依然稍显复杂,但借助于kubeadm之类的工具已然能够使得普通的系统管理员也可以较为轻松地部署Kubernetes,本书使用的也正是这种部署方式。另外,诸如Cloud Foundry Container Runtime、Canonical conjure-up和kops等工具的可用性也使得Kubernetes在数据中心和公有云环境中的部署变得更加简单。
于是,自定义或自主托管Kubernetes部署的模式正在受到越来越多人的关注,基于此种方式,用户可以在物理服务器、虚拟机和云计算环境中进行系统部署,其配置方式和部署体验据所用工具的不同而有所不同。
自定义的部署模式为用户的终极部署机制,他们可以从众多的目标部署环境、机器配置、操作系统、存储后端、网络插件和高可用性配置中进行选择。当然,在提供多样性选择和控制的同时,维护集群的责任将全部维系于用户自身。因此,此种模式中,用户需要为生产群集提供整个组件堆栈,包括从底层计算、网络和存储资源到镜像仓库等的安装、配置和管理。当然,在公共云环境中,一些资源(如虚拟机和块存储设备)则由IaaS服务商管理。
在操作系统、存储后端和叠加网络方面需要高度自定义的组织通常会选择自定义或自托管部署,毕竟此方法还提供了一些其他部署模式中可能无法提供的高级功能。自定义部署是最廉价的选择,因为客户只需要投资基础架构,用到的几乎所有的工具都是开源的,都可以从社区免费获取,但是组织必须考虑维护基础设施所涉及的人员和支持成本。
而那些希望在数据中心或公有云环境中运行Kubernetes而无须安装或维护集群的用户可选择托管的Kubernetes集群产品,提供托管Kubernetes服务的供应商则向用户收取集群的管理和维护费用,为此用户将不得不花费核心基础设施以及订购获得许可费用。托管的Kubernetes平台提供了两全其美的功能:基础设施的选择与免维护集群的结合。不具备安装、配置和管理大规模部署所需技能的组织可以选择托管的Kubernetes平台,如图13-8所示的带有独立边框的组件部分将由服务商负责。
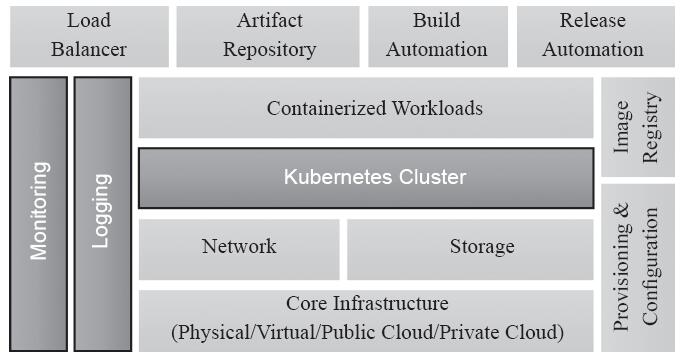
图13-8 托管的Kubernetes集群环境
由于平台供应商可以远程管理集群,因此用户可以专注于应用程序的开发,而不是维护容器基础架构。不过,与自托管部署相比,托管式Kubernetes产品更昂贵,毕竟组织将不得不考虑基础架构成本以及集群管理成本,好在管理Kubernetes平台的定期升级、修补、安全和监控服务的优势可以在长期预算范围内抵消一部分成本。此类的常见解决方案有IBM Cloud Private、Platform9和Tectonic等。
另外,早期的PaaS实现通常是基于隔离应用程序上下文的专有技术,而当Docker成为开源集装箱化技术时,PaaS服务商借助于容器取代了专有的执行环境。如今,大多数的PaaS产品都在容器上进行构建。虽然打包成为容器的程序代码仍然运行在虚拟机或物理服务器上,但Kubernetes已成为管理容器的事实上的编排引擎,那些传统的PaaS完全可以切换为构建在Kubernetes的基础上,提供端到端的应用程序的生命周期管理服务。
PaaS可以部署在公有云环境中或企业数据中心内部,很多大型组织正在采用PaaS来运行内部应用程序以及面向客户的应用程序,他们希望开发团队获得一致的体验,而不考虑部署目标是私有云还是公共云环境。基于Kubernetes的PaaS产品通过一致的工作流程和部署模式向企业提供了这一保证,甚至,在许多情况下,开发人员甚至不需要知道他们的代码将在Kubernetes集群内运行。这就意味着,PaaS层抽象了Kubernetes的底层细节,并且只公开了开发人员理解的API端点。
事实上,当DevOps工具部署于Kubernetes业务流程之上时,它就扩展成了一个容器类型的PaaS平台。开发人员不必处理打包容器的代码,因为平台包含将源代码转换为镜像的工具,并且平台会处理无状态服务和有状态服务之间的连接,开发人员也无须了解如何配置服务发现机制来发现内部和外部服务,如图13-9所示。不过,尽管PaaS降低了复杂性,但灵活性有所欠缺。
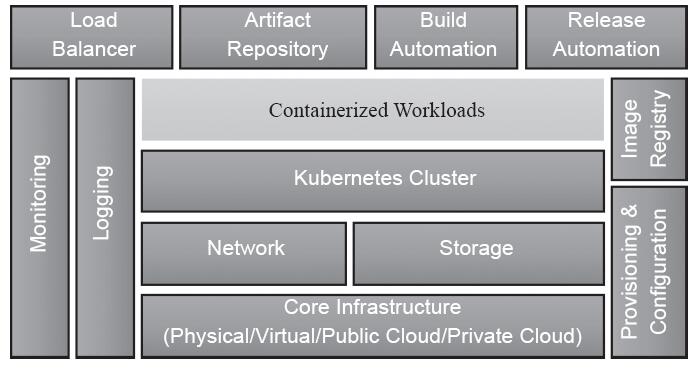
图13-9 基于Kubernetes的PaaS
自托管和托管的Kubernetes集群,其目标是管理员和DevOps团队,而基于Kubernetes的PaaS则是为开发人员所设计的,他们可以将源代码直接应用于平台上,而不是像Docker镜像或Kubernetes Pod那样打包的工件。他们不需要处理平台相关的任何操作,而仅需要关注代码和应用程序生命周期。Kubernetes已经成为现如今PaaS平台实践的基础,Red Hat OpenShift和Mesosphere DC/OS是著名的基于Kubernetes的PaaS产品。
最后,随着Kubernetes的成熟,其用例开始超越普通的容器编排服务而逐渐被用于多种小众场景中,这包括边缘计算(Edge Computing)、机器学习、无服务计算(Serverless Computing)和数据流分析(Stream Analytics)等,尤其值得一提的是新近兴起的无服务计算。目前,无服务计算与虚拟机和容器一起已成为公有云提供商提供的基本计算服务。不过,与其他计算服务不同的是,无服务计算基于事件驱动,开发人员以功能的形式将代码片段上传到无服务器平台后,它们只会在外部事件触发时执行,而非一直以后台进程处于守护运行状态。AWS Lambda、Azure函数和Google Cloud Functions是公有云中一些流行的无服务器计算选择。Docker可用于无服务器计算,于是Kubernetes成为在运行时管理这些Docker容器的首选项。Apache OpenWhisk、Fission、Kubeless、nuclio和OpenFaaS是基于Kubernetes的部署Serverless的项目。
1.5 容器时代的DevOps概述
DevOps的理论和实践起源于2009年前后,但最初应用的大趋势不温不火,直到容器技术出现并迅速流行开来之后,DevOps才日渐红火起来。究其原因,其中的一个可能性便是,容器是一个催化剂,它让DevOps文化的落地变得更加易于实现。
应用程序的设计架构从单体架构发展到分层架构之后,各种分布式协作的组件通常会由不同的开发团队来维护和交付,这些应用组件可能使用了不同的编程语言,依赖于不同的开发库环境及外部协作关系,这种系统架构部署和维护的复杂度为运维工作带来了极大的挑战,这一点通过1.5节中描述的DevOps各环节层出不穷的可用工具也可见一斑。如今,应用程序的分层架构进一步发展至微服务架构,开发人员获得便利的同时,运维工作的挑战性却有着进一步上升之势。
容器技术的出现使得运维工作复杂度不断上升的难题迅速得以冰消瓦解,DevOps在技术层面的落地不再是眼花缭乱的局面,它们被统一在容器镜像制作、分发和部署的纬度上。通过使用Dockerfile构建容器镜像,应用的配置和部署工作被提前到了编译时进行,这一点改变了之前制作好应用发布于不同的环境中之后再去手动调整环境变量的传统做法,于是,由于系统环境的差异所造成问题出现的可能性几乎降到了最低。
1.5.1 容器:DevOps协作的基础
容器技术解决了不同系统环境上应用程序的配置和维护的复杂度难题,从而使得开发人员和IT运维人员能够更紧密和更高效地协作,为DevOps的快速落地提供了一个极具效用的突破口。有了容器,传统DevOps实践中不得不为各种环境中应用程序的构建和释出进行复杂配置的局面,被容器技术极大地简化了。
借助Docker容器,开发人员可以做到将精力集中于容器中内容的构建(应用程序和服务,以及它们所依赖的框架和组件)以及如何将容器和服务协同在一起工作之上。当然,容器协调的编排机制有赖于编排工具的介入。相对应地,IT运维人员则可以将主要精力集中于生产环境管理方面,例如基础架构、系统扩缩容、监控,以及将应用程序正确交付到终端用户等,他们根本无须关心容器内容本身。
如图13-10所示,开发人员负责开发编写容器中运行的应用程序,他们通过Dockerfile来定义应用程序所依赖的系统环境,以及将代码构建到容器镜像中的步骤,并借助于编排工具的编排机制定义容器的协同方式。遵循业务环境需求,将制作好的Docker配置文件推送至项目的代码仓库中(如Git仓库)即可进入后续的步骤。
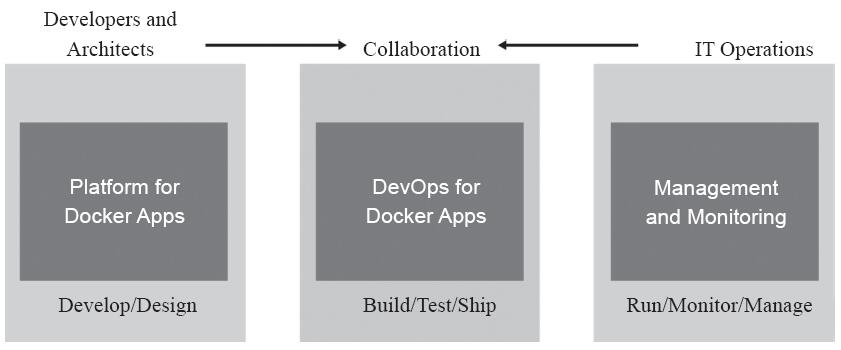
图13-10 容器模型中的DevOps(来源:microsoft.com)
接下来,在DevOps环节持续集成(CI)流水线从Git仓库中获取到的Dockerfile,结合从镜像仓库中拿到基础镜像自动构建自定义的容器镜像,并于制作完成后将其推送至选定的镜像仓库中以用于后续的部署操作。
随后,由CD(持续交付和技术部署)流水线自动完成基础设施构建、环境设定、容器部署和监控等工作,并将系统状态数据不断地反馈至开发团队。对于此环节来说,不同的团队的不同项目的自动化程度可能会有所不同,有的甚至还可能会由运维团队手工完成。
由此可见,开发和运维两个团队在容器平台的辅助下得以完成协同,从而大大缩短了软件开发的生命周期。开发人员负责维护容器的内容,而运维人员则负责在编排系统的辅助下将镜像运行为一个个的容器。
1.5.2 泛型端到端容器应用程序生命周期工作流
图13-11提供了更详细的Docker应用程序生命周期的工作流,其着重描述了DevOps的活动和资产。
DevOps流程始于开发人员,他们在自有的内部循环中编写并调试程序代码,而后将“稳定”状态的代码推送至代码仓库(如Git)中。提交完成后,代码仓库将触发CI和工作流的其余部分。
DevOps工作流不仅仅是一个工具集合,它更是一种软件开发演进而来的文化,它是使得软件开发更敏捷及可预测的人员、流程和相应的工具的集成。于是,采用了容器化工作流的组织就需要基于容器工作流来重构他们的组织及其工作机制。实践DevOps,以自动化取代手工劳动从而大大提升效率并降低出错的可能性,从而帮助组织或企业内容更高效地协作以获得更好的竞争优势。另外,组织还可以结合云计算按需为系统配置资源,实现更高效的环境管理和资源利用最大化,节约运行成本。
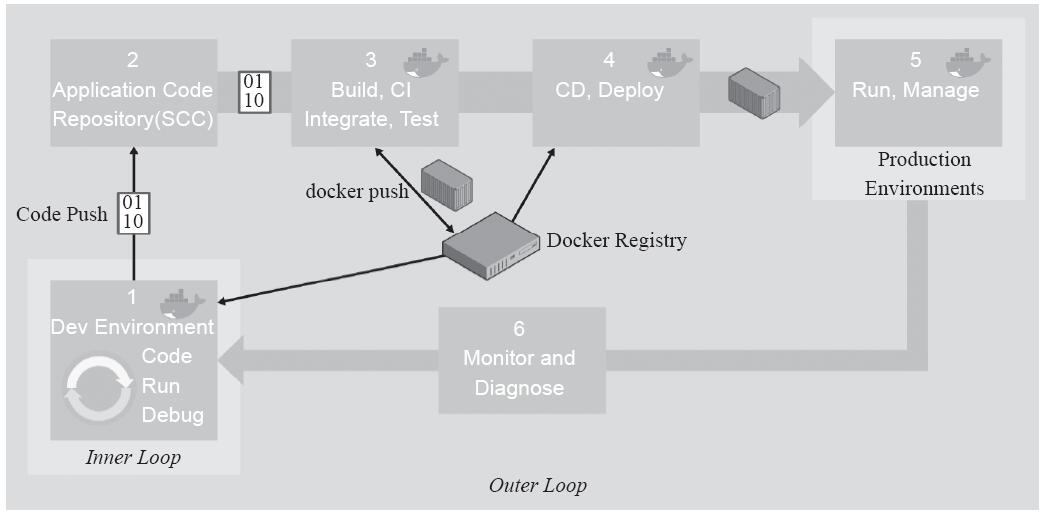
图13-11 泛型端到端容器生命周期工作流(来源:microsoft.com)
1.5.3 基于Kubernetes的DevOps
在DevOps工作流中,Kubernetes作为运行时环境中的编排工具,用于容器的编排运行。例如,如图13-12所示的DevOps工具链中所展示的DevOps工作流包括如下内容。
1)开发人员编写应用代码推送至Git上的代码仓库,而后经CI工具链构建、测试后释出。
2)开发人员编写Dockerfile推送至Git上的项目仓库中,而后基于基础镜像和释出的应用程序构建Docker镜像,并推送至Docker仓库中。
3)开发人员编写Kubernetes清单(manifest)或helm charts,而后由kube applier应用(创建或升级)至Kubernetes集群加以运行。

图13-12 基于Kubernetes的DevOps工作流
kube-applier是一种服务,在集群中作为Pod运行,并监视Git仓库,通过将声明性配置文件从Git存储库应用到Kubernetes集群,实现持续部署资源对象。图13-12显示的工作流中,Jenkins是整个CI/CD流水线的Hub,它经由Git WebHook触发控制着CI、镜像构建、Kubernetes Pod创建和编排等一应操作。
此种场景中,Jenkins承担了太多的工作,CI、镜像构建、基础环境、应用部署均由其负责实施,每当有团队需要做一个新的部署流水线时,就会根据具体需求进行微调,必要时还得重写所有的脚本,效率略低。对于有研发实力的组织,可以把关键的工作做成单独的系统,例如,不再把构建组件和部署组件作为Jenkins的插件,而是分别做成独立的系统。
另外,DevOps的流程中需要的各种工具链几乎都可以托管于Kubernetes平台之上运行,包括Jenkins。此时,再加上Kubernetes平台支持的调度、健康检查、日志、监控、安全、应用服务、弹性扩缩容和服务发现等功能,就是一个完整的容器云平台。不过,有些开源项目本身已经直接集成了这些功能,如OpenShift和Tectonic等。
1.6 小结
本篇主要讲解了自定义资源类型CRD、自定义资源对象、自定义控制器、自定义API Server及API聚合等Kubernetes API的扩展方式,给出了Kubernetes集群高可用架构中控制平面的实现机制,并说明了生产环境中Kubernetes集群的常见部署方式。
版权声明:如无特殊说明,文章均为本站原创,版权所有,转载需注明本文链接
本文链接:http://www.bianchengvip.com/article/Kubernetes-High-Availability-and-Custom-API-Server/